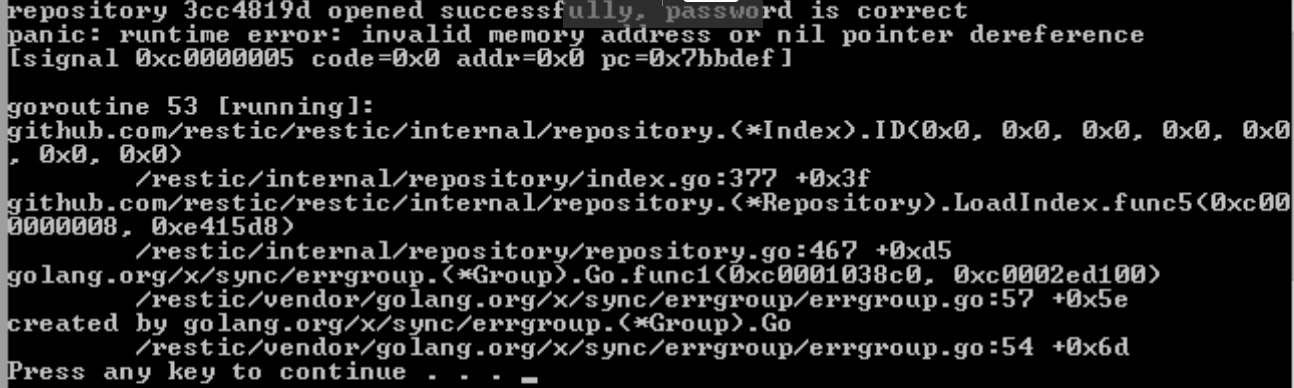
Uh, congratulations, you found a bug! 
Did restic print anything before the panic? Like, was there an error loading an index file?
I assume this is restic 0.9.5, is that right?
What happens here is that restic tries to load the index files and somehow fails, and then it does not correctly check for errors. It all starts in LoadIndex() here:
idx, buf, err = LoadIndexWithDecoder(ctx, r, buf[:0], fi.ID, DecodeIndex)
if err != nil && errors.Cause(err) == ErrOldIndexFormat {
idx, buf, err = LoadIndexWithDecoder(ctx, r, buf[:0], fi.ID, DecodeOldIndex)
}
select {
case indexCh <- idx:
case <-ctx.Done():
}
Some worker function loads an index, checks for a specific error (ErrOldIndexFormat) and handles that, but does not check for other errors! So it may happen that err is set, and idx is nil. This nil index is then sent to indexCh.
In another Goroutine, a different function collects the loaded indexes here:
for idx := range indexCh {
id, err := idx.ID()
if err == nil {
validIndex.Insert(id)
}
r.idx.Insert(idx)
}
It receives an index in the variable idx and calls the ID() function on it. If the received idx is nil, a panic happens in that function here:
func (idx *Index) ID() (restic.ID, error) {
idx.m.Lock()
When idx is nil, then there’s no idx.m, so that’s when it panics.
Your run of restic rebuild-index rewrote the index files and removed the old ones, and somehow the error went away. It could either be an error accessing the index file at the repository or the local cache, unfortunately I cannot tell that.
I’ve managed to reproduce the issue locally:
- Create a new repo in
/tmp/foo, remember repo ID
- Make a backup
- Run
chmod 000 /tmp/repo/index/*
- Remove the cache via
rm -rf ~/.cache/restic/ID
- Run
restic backup again:
repository 692de0f7 opened successfully, password is correct
created new cache in /home/fd0/.cache/restic
Load(<index/6b8f24ac36>, 0, 0) returned error, retrying after 552.330144ms: open /tmp/foo/index/6b8f24ac368d06aec6bddec3e0f915adc876267caf2fd52596f8af5f7b934225: permission denied
[...]
Load(<index/6b8f24ac36>, 0, 0) returned error, retrying after 13.811796615s: open /tmp/foo/index/6b8f24ac368d06aec6bddec3e0f915adc876267caf2fd52596f8af5f7b934225: permission denied
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x7bef48]
goroutine 54 [running]:
github.com/restic/restic/internal/repository.(*Index).ID(0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)
/home/fd0/shared/work/go/src/github.com/restic/restic/internal/repository/index.go:377 +0x38
github.com/restic/restic/internal/repository.(*Repository).LoadIndex.func5(0x8, 0xe75950)
/home/fd0/shared/work/go/src/github.com/restic/restic/internal/repository/repository.go:467 +0xce
golang.org/x/sync/errgroup.(*Group).Go.func1(0xc000372750, 0xc000392240)
/home/fd0/shared/work/go/pkg/mod/golang.org/x/sync@v0.0.0-20181221193216-37e7f081c4d4/errgroup/errgroup.go:57 +0x57
created by golang.org/x/sync/errgroup.(*Group).Go
/home/fd0/shared/work/go/pkg/mod/golang.org/x/sync@v0.0.0-20181221193216-37e7f081c4d4/errgroup/errgroup.go:54 +0x66
I’ll create a PR which fixes this shortly.