@fd0 Here you go, happened again. It was working fine but I had to CTRL+C a client backup to make some changes. When I tried again, I got this:
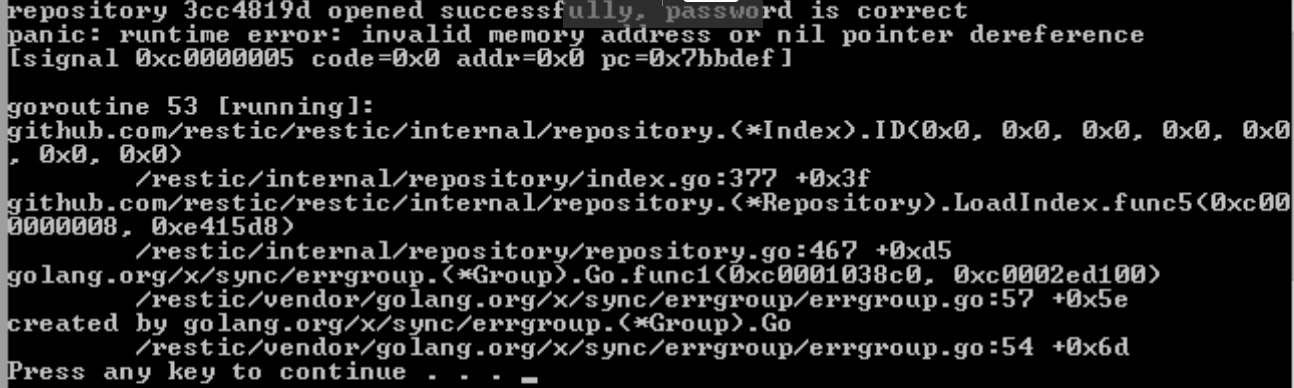
I deleted the caches, it didn’t help. Having to run rebuild-index again.
Funny thing is I have an exact clone of the repo. I did a sync from the working one to the new one that just broke. Nothing changed, and it still won’t back up. Just throws that error. Doubt rebuild-index is going to help but I’m giving it a shot overnight.
I should mention it’s the same Server 2008 R2 client as before, too.