Hello @David,
Again, many thanks for your reply! More below:
Not sure about that, see below.
My response below is a little orthogonal to your original inquiry, and if that’s totally unsatisfying, please let me know.
Not a problem. It helped point me towards what has became, if not a solution, at least an acceptable work-around for the moment.
In short: The slowdown trend you are seeing (and which is illustrated in your original graph) is not caused by the growing repository size, but instead by the quantity of files changing on each day
Not sure about that; if I understand your hypothesis correctly, then we should see some definite linear correlation tendency when plotting “Seconds to complete / files changed” for each backup, which we don’t:
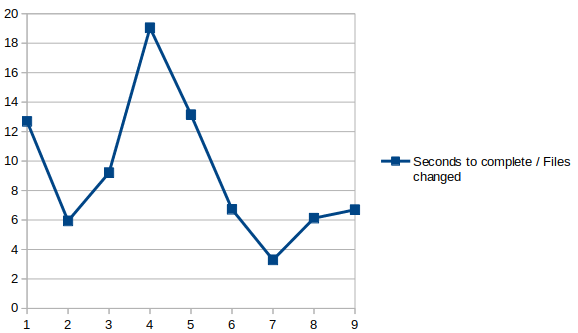
For example, your fastest backups were 1,2,3,4 and 5. If you examine the “Added to the repo” number in your stats messages, you will see that these backups averaged 1.14 GiB “Added to repo” per backup. (1.65, 0.78, 1.24, 1.17 GiB respectively)
Oh, OK: from the above I gather you are not referring to the “Bytes added to the repo resulting from the new/changed files”, and not literally to the “quantity of files changing” as I understood at first; Let’s graph that too (seconds to complete / Bytes added to the repo):
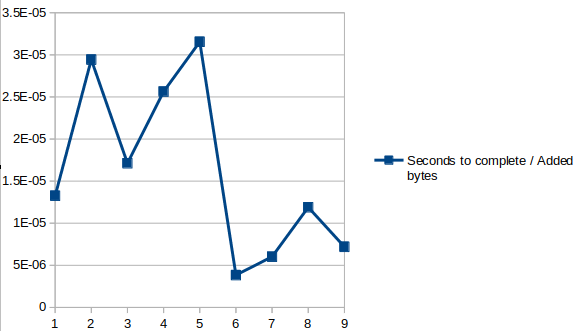
(BTW, no need to refer to the stats messages, the “Bytes added to the repo” was already in my CSV file as column F).
So, at least graphically, it doesn’t seem to be correlated either.
Your slowest backups were 6,7,8,9. These backups averaged 7.3 GiB “Added to repo” per backup. (10.0, 8.2, 3.7,7.6 GiB respectively). This is why they ran so much longer - they wrote six times more data to the repository.
This is indeed the case, but it could be coincidence as your hypothesis seems to be contradicted not only by the above graph, but also by some individual observations like the fact that backup 7 was the longest at 55% more “seconds to complete” than the second-longest, which was backup 6, but the latter added ~10.7GB to the repo, while the former added almost 20% less at 8.8GB.
Another factor that helps disprove the “more bytes” explanation is that I have a 50Mbps symmetric internet link for the backup – but (after the initial restic backup) its upstream utilization never goes beyond 10Mbps. And in fact, 10.7GB / 41115 secs * 8 = ~2.1Mbps, so the “more bytes” could hardly be an explanation, at least in terms of effectively-used upstream bandwidth.
OTOH, this backup’s duration seems to have stabilized around 14h – hardly comfortable, but at least it’s not in imminent danger of exceeding my roughly-24h backup window, so I think I have more time to finally solve that.
Some further comments:
- I would definitely still seek an answer to your original questions of “How can I perform occasional forget/prunes on this repository” and “what is the most efficient way to do so”. I just think it’s commonsense that you will want to run those operations occasionally.
I think I will post another topic regarding that, as this one has strayed far and wide from its original intention ![]()
- I might explore whether you could achieve substantial performance gains by executing this backup to local storage, and then synchronize that storage to the cloud. (This is what I do!).
[/quote]
The problem with that approach is that I don’t have enough free local storage for that, and besides I’m not very happy in adding another stage to that cloud backup (I already have a first stage where the backed-up datasets are sync’ed byzfs send|recvfrom the main server to the backup server, where I run restic to back it up to the cloud).
Thanks again,
– Durval.