I have a folder with approx 125k files in 35k subfolders with a total of around 10 GB on disk. Only a low percentage of files will change, always more or less the same files, on a daily base.
Using restic I will backup this data over sftp to a remote server.
Performance-wise, would it be more efficient to first rar the whole dir and then let restic do the deduplication and transer or run restic directly on the directory and let it handle those 125k files?
I see absolutely no reason to rar the whole dir first. Run restic backup and it will scan the directories and detect which files have changed since the last backup (of the same backup set) and only read through those that have.
As far as i understand, restic is comparing (kind of) hashes on (kind of) block level. So createing a rar would compress those tons of files resulting in a much smaller rar file. Therefor i thought maybe the operation of deduplication could be faster.
Transferring lot of files over the network create quite a lot of overhead communication (and also processing). So I was thinking it might be a benefit to only have one rar file.
Well you can probably benchmark it and compare its results. It probably won’t make a lot of difference all in all.
The downside of this would be that you would not be able to restore a certain file or folder from a given snapshot as they are tar’ed. You also won’t be able to diff snapshots or see what changed when making a backup. If this information would be of no value to you anyway then I would, as I said, benchmark it and see what works best for you and your environment.
I will do a benchmark to find out - i was asking since i thought maybe from knowing how restic is working inside it might be obvious if one or the other method will be faster. If it doesn’t really make a difference, I’m with you, then the no-rar method i will prefer for the reasons you are pointing out.
On your first point, compression actually makes it very difficult to deduplicate. You may see an initial “smaller” snapshot, but as you create new RARs in the future, it will store much larger chunks of the RAR all over again, since so much of a compressed archive can change in between compression runs. So the net result is larger overall backups. Don’t do this.
You need to deduplicate first, THEN compress - which, coincidently, the latest builds of restic do just that. Compression is now built into Restic going forward. Restic will dedupe and compress on the fly! So use these until it’s in the main branch, and you can have the best of both worlds.
See this thread for more info and how to migrate your existing repo.
Thanks a lot for the hint and insight. I completely missed the compression feature.
I will wait for the main branch and with your 30 days migration journey in mind think about if i’m going to migrate old snapshots at all or if i just create new repos and start reducing the old ones over the next 12 months.
From what i read in the thread you linked it seems with v2/compression the runtime increased significantly (which seems to be logical as compression eats quite some cpu time). So performance-wise, would it be fair to state we traded in more runtime/cpu load against smaller storage space and reduced transfer bandwith?
The migration itself is pretty swift. About the same time it takes to run a restic check. What might take awhile is restic prune --repack-uncompressed - but you can add --max-repack-size 250G and do it sporadically over time / scheduled at night.
Mine took awhile because (a) I did it in small batches, only at night, and ran backups during the day, (b) I used restic copy since I was an early adopter and restic prune --repack-uncompressed wasn’t implemented yet, and (c) because I used --max-compression, which, honestly doesn’t save that much more space over auto. I wouldn’t bother unless you’re paying by the gigabyte like I am with B2.
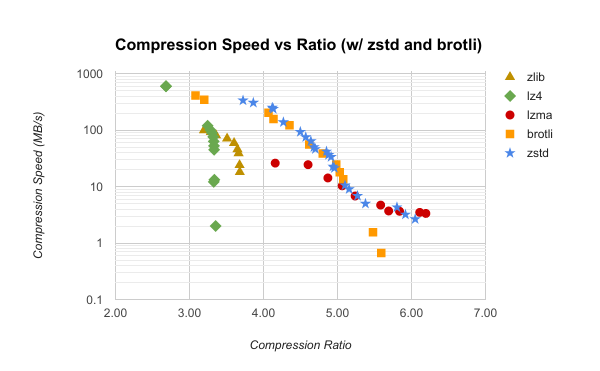
Here’s a benchmark of zstd on my machine. Second to last column is compression speed. Last column is decompression speed. I am uncertain what exact levels Restic uses for --compression auto (the default) and --compression max but I’d wager auto is somewhere between 1-4 and max is probably somewhere between 12-19. (If someone knows the exact settings, please chime in!) Which is why with auto you’re not really going to notice a difference straight to disk, but you might get a performance increase when using a remote repo since the bandwidth is most likely your biggest bottleneck. Zstandard compression is known for being extremely fast, yet compressing more efficiently than say, LZ4 or zlib.
On one end, zstd level 1 is ~3.4x faster than zlib level 1 while achieving better compression than zlib level 9! That fastest speed is only 2x slower than LZ4 level 1. On the other end of the spectrum, zstd level 22 runs ~1 MB/s slower than LZMA at level 9 and produces a file that is only 2.3% larger. Source
Also Restic compares the compressed blob with the uncompressed version, and if the uncompressed version is actually smaller, it stores that instead (with either compression level). Handy when some of your data is already compressed (MP4, JPEG, etc).
TL;DR: If you’re comfortable, go ahead and migrate now! New backups (just the new, unique packs) will be compressed with auto by default. Old backups (individual packs) will remain uncompressed until you run prune --repack-uncompressed (with optional --compression max and --max-repack-size 300G). You can do it all in one fell swoop, or use the latter optional flag to do it in small batches. If you run prune regularly anyway, just include --max-repack-size 25G or something in your scripts and over time it’ll take care of itself.
@AnAnalogGuy Also to give you an idea of what you’ll get from this, I did a restic stats on JUST the latest snapshots from each host. In restore mode, it’s 10.285 TiB. In files-by-contents mode (so, deduped), it’s 4.577 TiB. And in raw-data mode (compressed), it’s 3.013 TiB.
IIRC, this is not true. The argument was that even for already compressed data, the zstd overhead is really small. So it doesn’t matter to always save the blobs compressed.
I think “it” means what the zstd algorithm is doing, not what restic is doing.
You can easily check it yourself: Run prune --repack-uncompressed. I think this will never try to repack such data as it is stored as “compressed” (which in fact means, the data has been processed by the zstd enciding algorithm - which of course could have decided to just save the raw data)