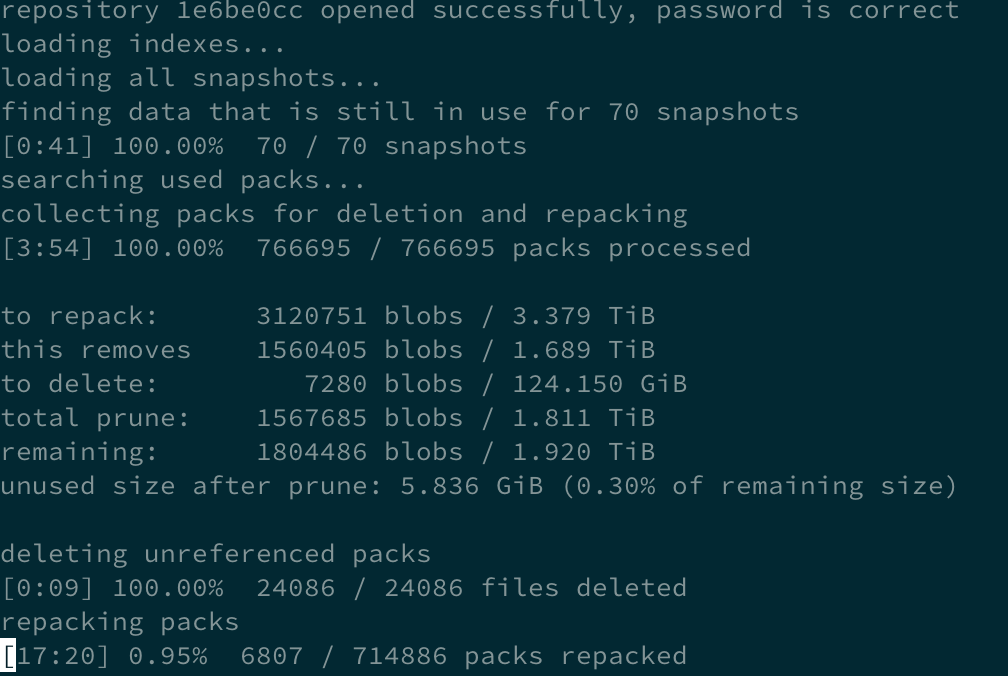
I have a (large?) repository with about 2.1Tb of data; I add a dozen snapshots each work day, then wanted to forget/prune in the weekend. Unfortunately, the prune operation is so slow that at the current rate it would take over 300hours, so clearly I can not perform it without stopping the hourly backup for a long time.
You should probably include the complete command and what repository backend you use with the information in the screenshot.
But assuming you are using restic 0.12.0, which it looks like, you are using the version that has dramatically improved prune performance and should work as fast as it can.
Are you perhaps on a slow Google Cloud backend? How long has it been since you pruned last time?
Your current prune operation is slow because it wants to repack many packs. This might be due to duplicates (maybe because of aborted backup or prune) which are not perfectly handled in 0.12.0. There is
but this still needs a review and should so far not be used in a production repository.
EDIT: If it is possible for you to copy your repo, I would be very much interested in you testing this PR
You can try to play around with the parameter --max-unused. If this is set to unlimited ,only duplicates and tree packs will be repacked.
Moreover, you can use --max-repack-size to limit the size which is actually repacked. This should also work with duplicates.
Always try with --dry-run to see what prune intends to do and run it without when you are satisfied with the choice of your parameters.
So, the file server and the restic server are on the same network, accessed via SFTP, I’m currently using restic 0.12.0.
I managed to perform the prune in about 26 hours by running it directly in the server, my next automatic prune operation happens tomorrow, I hope this will be quicker