First of all let me say thank you for such an awesome tool restic is. About a couple weeks ago I’ve started to look for a replacement for macOS Time Machine and amount of custom rsync --link-dest scripts and rustic is almost what I’ve designed to for that time to be implemented on my own and even covers some tricky scenarios. And especial thank you for such a fundamental approach in the design process with specifications and so level-wide documentation which have high level information for users and deep details for developers!
But here are some questions
In docs you’re saying the default pack size is 16M and noted on rotational HDDs and fast network connection it could be inefficient in some cases (which is actually my case) so I wonder if there’s a way to migrate packs between sizes? It’s OK to do that within the process of snapshot copy to another repository. i.e. repack during the copy or even create new repository and manually copy all snapshots there in any scriptable way - so I normally have no limitations here.
Why is the maximum pack size is 128M ? In my previous tools I’ve used macOS sparsebundle images with band size of 128M-2G depending on what the data inside so values lower 128M doesn’t look efficient enough in my previous cases, is there a technical reason to use 128M at max?
You have awesome integrity check feature with or without data verification (and authentication) but what to do if something reveals broken? Probably simply use another snapshot, but if I definitely have another copy of the same data in another place since my backup strategy contains multiple remote data copies, could I simply replace corrupted packs?
The same question #3 in another approach: why couldn’t restore corrupted packs by using redundancy mechanisms such as erasure coding with Reed-Solomon algorithm (like WinRAR does) or XOR-based (like in RAIDs 4/5/6) or whatever similar ? It will definitely increase repository size but will make recovery possible.
I’m using restic with a couple rclone backends so I’ve noted restic uses STDIO to interact with rclone which limits multiplexing requests from restic to rclone, why not to use any kind of TCP IO (like HTTP) ? PS. I already tried to play with amount of connections (rclone: --transfers, restic: -o rclone.connections) and it partially helps, but I still see some gaps on network utilisation graph even when setting 48 connections to use.
It’s possible to repack too small pack files using restic prune --repack-small --pack-size size. Using copy to move all data to a new repository is also possible, as copy transfers the data blobs contained in pack files, but not the pack files themselves. This leads to the construction of new packs, with the specified pack size.
Restic uses HTTP2 to speak with rclone which natively implements multiplexing. I’d expect that it should be possible for restic to send at least 1GB/s to rclone (I have no numbers to back that up). Can you describe you setup a bit further?
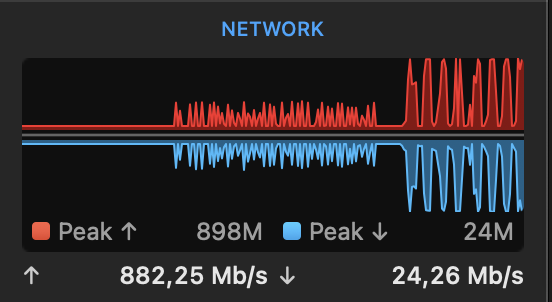
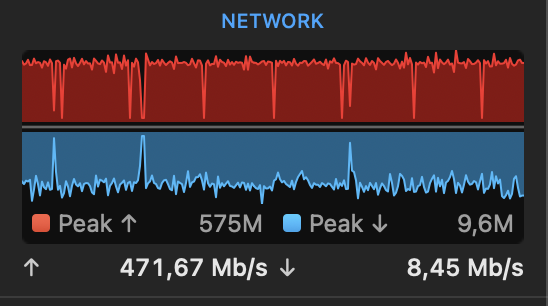
Sure, I’ve got such results while made snapshots copy from local repository to remote one via rclone (macOS 13.4, rclone v1.62.2, restic v0.15.2). $TMPDIR and --cache-dir are set to (the same) dedicated NVMe SSD, local repository is placed on RAID array of rotational HDDs (both drives are connected over Thunderbolt 3 connection, SSD on its own bus, RAID on its own one). rclone has proven 1Gbps bandwidth to that configuration --transfers=24 in sync mode.
So what I see:
Bandwidth spikes between 11Mbps-700Mbps like that
Sometimes outgoing traffic goes to almost zero bps for a couple of seconds, like rsync waits something or restic does something before sending the request
So to exclude any local stuff here’s an experiment to copy snaphots:
the same OS and restic/rclone versions
repository on NVMe SSD initialised with default options
remote repository configured via rclone (no crypto or any other stuff, just a plain backend)
data of 10x 1G random BLOBs
Graphs made by iStat menus
And two cases to check
case 1: copy with default rclone options (left upload spikes)
case 2: rclone.args ... --transfers=48 + restic ... -o rclone.connections=48 (right upload spikes)
What makes doubts for me here on that graph: when you’re using rclone to sync some files increasing the amount of transfers allows you to “overlap” connections data streams for better network utilisation, i.e. when you have 48 transfers even if half of them are waiting for backend or disk IO 24 left could utilise the whole data channel. And this graph shows it works another way with restic, for me it looks like there’s some kind of goroutine locking after or before new file is sent to rclone. Probably it’s up to rclone since I haven’t done deeper investigation yet.
I most likely got what it was: some cloud services requires some time to generate upload URL to send data to, I’ve used default parameters of restic when created the repository so my chunks was about 16M in size and the was uploaded to fast to make a described behaviour of utilising the network.