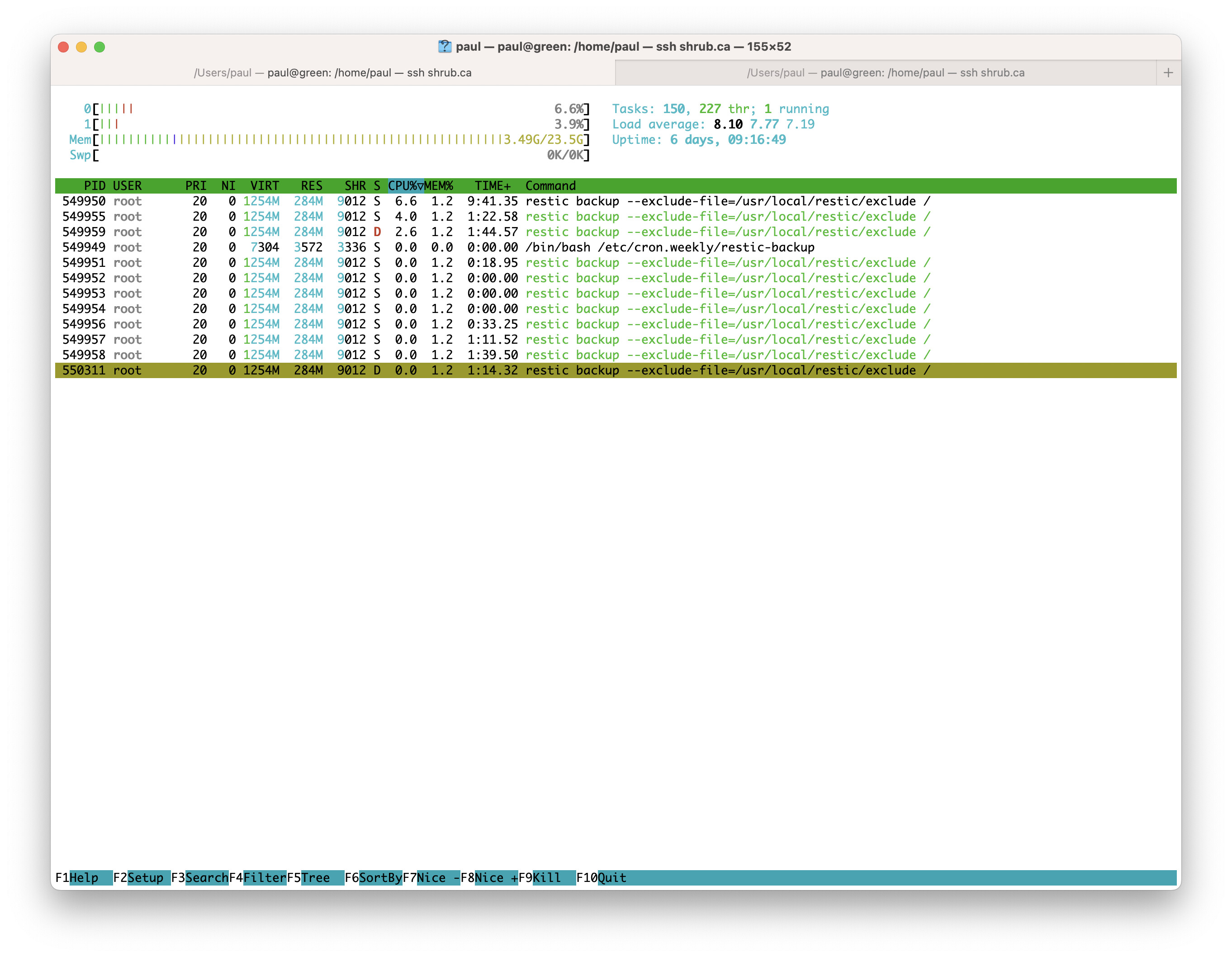
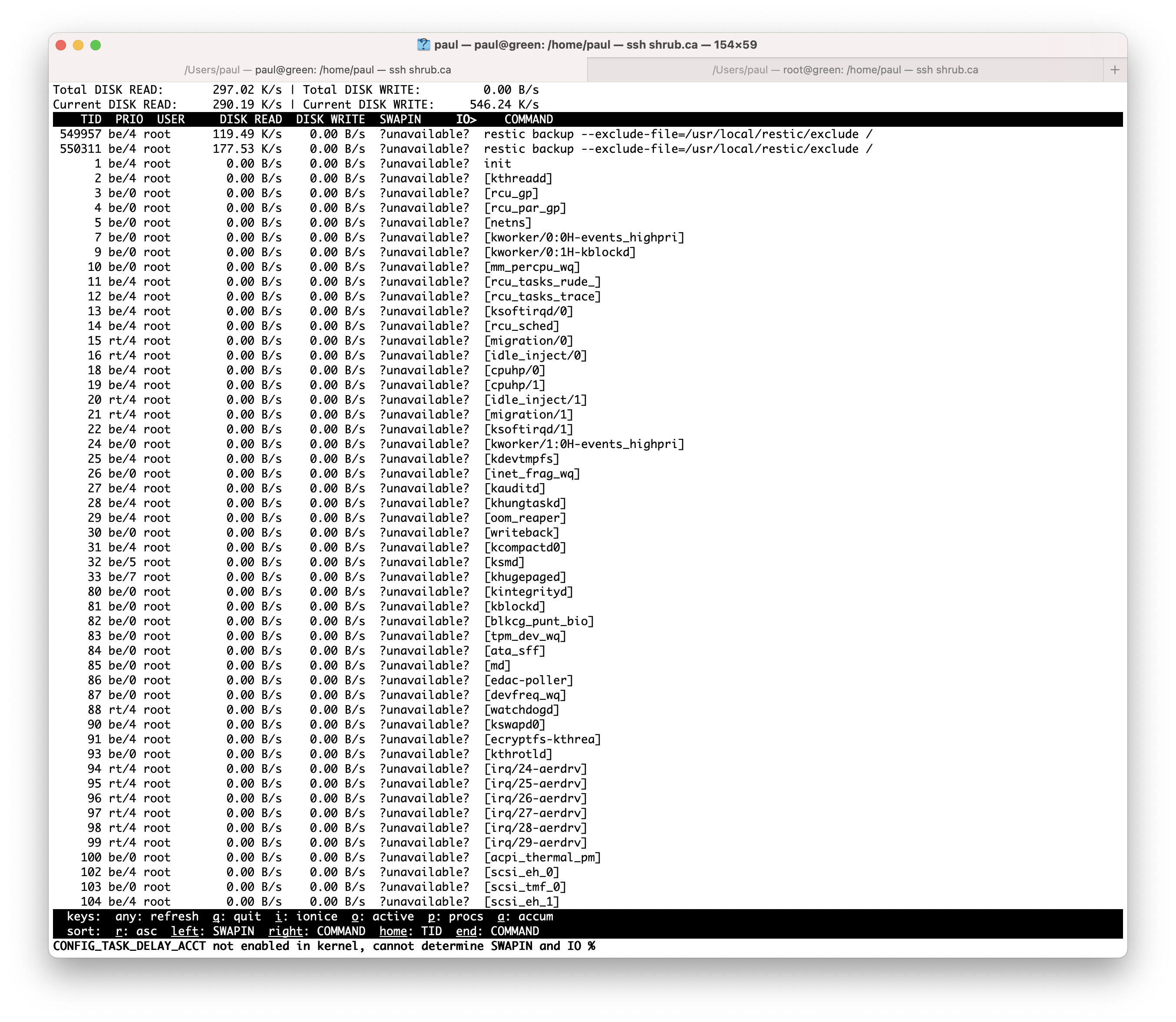
Here’s some strace output from one of the child processes:
# strace -p 549951
strace: Process 549951 attached
restart_syscall(<... resuming interrupted read ...>) = -1 ETIMEDOUT (Connection timed out)
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
futex(0x18c7298, FUTEX_WAIT_PRIVATE, 0, {tv_sec=0, tv_nsec=793301858}) = -1 ETIMEDOUT (Connection timed out)
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
epoll_pwait(3, [], 128, 0, NULL, 0) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
getpid() = 549950
tgkill(549950, 549959, SIGURG) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
futex(0x18c7298, FUTEX_WAIT_PRIVATE, 0, {tv_sec=0, tv_nsec=996592347}) = -1 ETIMEDOUT (Connection timed out)
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
futex(0x18c7298, FUTEX_WAIT_PRIVATE, 0, {tv_sec=0, tv_nsec=999518218}) = -1 ETIMEDOUT (Connection timed out)
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
futex(0x18c7298, FUTEX_WAIT_PRIVATE, 0, {tv_sec=0, tv_nsec=999612353}) = -1 ETIMEDOUT (Connection timed out)
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
futex(0x18c7298, FUTEX_WAIT_PRIVATE, 0, {tv_sec=0, tv_nsec=999292713}) = -1 ETIMEDOUT (Connection timed out)
nanosleep({tv_sec=0, tv_nsec=20000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=40000}, NULL) = 0
nanosleep({tv_sec=0, tv_nsec=80000}, NULL) = 0
futex(0x18c7298, FUTEX_WAIT_PRIVATE, 0, {tv_sec=0, tv_nsec=999107358}) = -1 ETIMEDOUT (Connection timed out)
Is the sleep/timeout combo expected?