We are searching for a Borgbackup alternative that can help us achieve faster backups. With borg, we are limited by the single connection bandwidth limit.
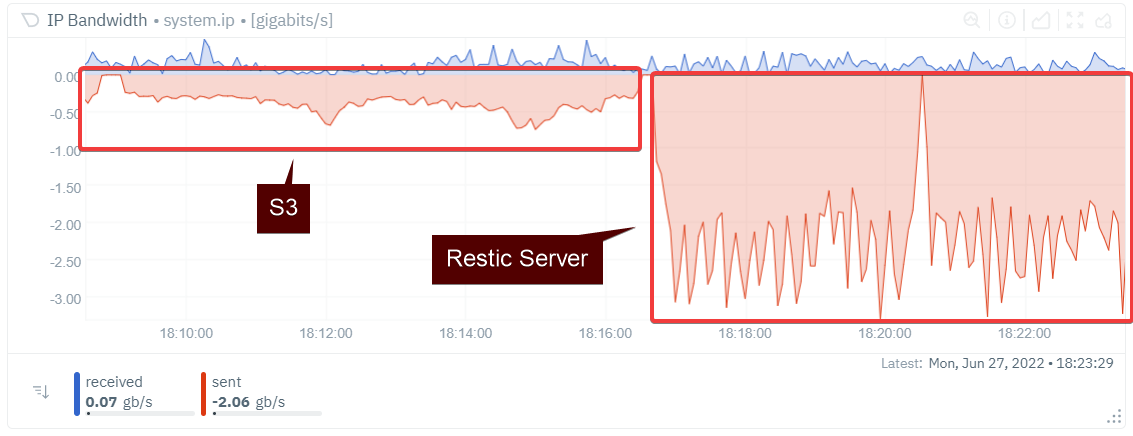
While Restic uses concurrent uploads we are getting poor performance from S3 vs Rest Server.
With S3 we are looking at around 800M for the initial backup and 200-400M for incremental backups.
For Restic Server we are always in the > 2G space.
Both S3 (Minio) and Rest Server are on the same machine. With iperf3 the speed is > 8G between them.
We are getting way better Minio performance with other applications.
Does someone know what the S3 implementation bottleneck is and if what we are seeing is normal?
Is there anything that can be tuned to get S3 into the G space?
Not much, you can try different -o s3.connections=N values to check if this will bring an improvement. But I am not sure if that’s essentially same thing of the PR linked above.
Does maybe MinIO or rest-server use http/1.1 and the other one http/2? Does setting GODEBUG=http2client=0 as environment variable for restic change anything?
My guess right now would be that MinIO takes more time to store uploaded data than the rest-server. At least that would be consistent with the reported numbers. Although I’m not completely sure how the external S3 would fit into that picture. Ultimately the proper solution to improve the upload speeds will be larger pack files, everything else is just too latency sensitive to max out the network connection.
With the increase in connections and the async PR, we are able to hit an average of 3G with internal and external S3 (only one wasabi location) as well as with the Rest server.
We are unable to get anywhere beyond that. What we have found is that if files look changed (hard link changed, still the same file) and restic does the chunk comparison → this speed is not far off from the average 3G transfer speed.
Are there any options to speed up this chunk comparison or do you have other thoughts on what the new bottleneck is?
→ I am aware that we need to set --ignore-ctime to work around the changing hard-link issue. But it likely runs the same logic for new files and it is possible that this the bottleneck there.
The next bottleneck is probably reading / chunking data. Currently only two threads read and chunk data. Especially the chunking part is limited to a few hundred MB/s per thread. You could try to increase that number in the source code.
Besides that there are probably some other bottlenecks somewhere, although I can’t tell where so far .
Does the backup data set consist of many small files or rather of large files?
That is somewhat unexpected. Although the behavior could change drastically, now that I’ve merged PR #3489 (the async PR). The pack-size PR sort of only increases the pack size and does very little else. At least for a normal HDD as target, larger pack sizes drastically improve throughput as this requires a lot less flushing files to disk. My expectation for rest-server / S3 would have been exactly the same, as both also have to flush files to disk and thus larger pack files put less stress on the IO-subsystem. But it looks like we ran into some other bottleneck somewhere…