I have ready about 2 different posts on this matter for instance this. For my post I want to add as much context to understand where or what I can do to tune this.
I run an UnRAID server (AMD Ryzen 3900x 12 core machine with 64GB of RAM) with 10TB of data. I run restic using autorestic which is just a wrapper to use a config file to backup. I back up to a server inside my house that is a TERRAMASTER F4-223 (Intel Celeron N4505) that runs also UnRAID with a 14TB drive using restic rest server docker container. This is connected via 1Gbps ethernet cable.
I run backups daily at 2AM, but sometimes the backup takes forever as we speak my current backup to this local Terramaster has been running since 2AM and it is now 4:24PM so it has been running for 14hours, but the day before it took 25:24mins. Between now and then I did not do anything. I may have moved files around but the majority of the files are sitting in the same place.
I also did check and for both yesterdays backup and today’s backup a parent snapshot is being used. Does anyone have any ideas on what other thing I should check?
I have to figure out what it is doing since right now my backup turns off some containers and puts my nextcloud container in maintenance mode which is unusable.
Here is the log of the successful run:
Backing up location "array"
Running hooks
> curl -fsS -m 10 --retry 5 -o /dev/null --data "Starting backup to location ${AUTORESTIC_LOCATION}" -X POST https://hc-ping.com/{UUID}/start
> Executing: /usr/bin/bash -c curl -fsS -m 10 --retry 5 -o /dev/null --data "Starting backup to location ${AUTORESTIC_LOCATION}" -X POST https://hc-ping.com/{UUID}/start
> bash before.sh
> Executing: /usr/bin/bash -c bash before.sh
Starting database backup script
Database backups found in /mnt/user/appdata/autorestic/databases/. Removing...
Database backups removed successfully.
Checking Nextcloud maintenance mode status
Maintenance mode is currently disabled. Turning it on...
Nextcloud maintenance mode turned on successfully.
Stopping freshrss
freshrss
Stopping ghost
ghost
Creating backup of nextcloud database
Creating backup of freshrss database
Creating backup of ghost database
Creating backup of photoprism database
Database backup process completed successfully
Backend: local
> Executing: /usr/local/bin/restic backup --tag ar:cron --tag ar:location:array /mnt/user /boot
using parent snapshot 1889def7
Files: 6396 new, 391 changed, 793626 unmodified
Dirs: 134 new, 242 changed, 168041 unmodified
Added to the repository: 19.102 GiB (10.454 GiB stored)
processed 800413 files, 8.874 TiB in 25:24
snapshot 60de5e4f saved
Backend: remote
> Executing: /usr/local/bin/restic backup --tag ar:cron --tag ar:location:array /mnt/user /boot
using parent snapshot de57f616
Files: 6396 new, 391 changed, 793626 unmodified
Dirs: 134 new, 242 changed, 168041 unmodified
Added to the repository: 18.811 GiB (10.316 GiB stored)
processed 800413 files, 8.874 TiB in 24:07
snapshot 59bbc8ce saved
Running hooks
> bash after.sh
> Executing: /usr/bin/bash -c bash after.sh
Starting freshrss
FreshRSS started successfully.
Starting ghost
Ghost started successfully.
Checking Nextcloud maintenance mode status
Maintenance mode is currently enabled. Turning it off...
Nextcloud maintenance mode turned off successfully.
Service restoration completed successfully
Here is the current log that is still running.
Backing up location "array"
Running hooks
> curl -fsS -m 10 --retry 5 -o /dev/null --data "Starting backup to location ${AUTORESTIC_LOCATION}" -X POST https://hc-ping.com/{UUID}/start
> Executing: /usr/bin/bash -c curl -fsS -m 10 --retry 5 -o /dev/null --data "Starting backup to location ${AUTORESTIC_LOCATION}" -X POST https://hc-ping.com/{UUID}/start
> bash before.sh
> Executing: /usr/bin/bash -c bash before.sh
Starting database backup script
Database backups found in /mnt/user/appdata/autorestic/databases/. Removing...
Database backups removed successfully.
Checking Nextcloud maintenance mode status
Maintenance mode is currently disabled. Turning it on...
Nextcloud maintenance mode turned on successfully.
Stopping freshrss
freshrss
Stopping ghost
ghost
Creating backup of nextcloud database
Creating backup of freshrss database
Creating backup of ghost database
Creating backup of photoprism database
Database backup process completed successfully
Backend: local
> Executing: /usr/local/bin/restic backup --tag ar:cron --tag ar:location:array /mnt/user /boot
using parent snapshot 60de5e4f
Way to much unknown variables here to answer properly.
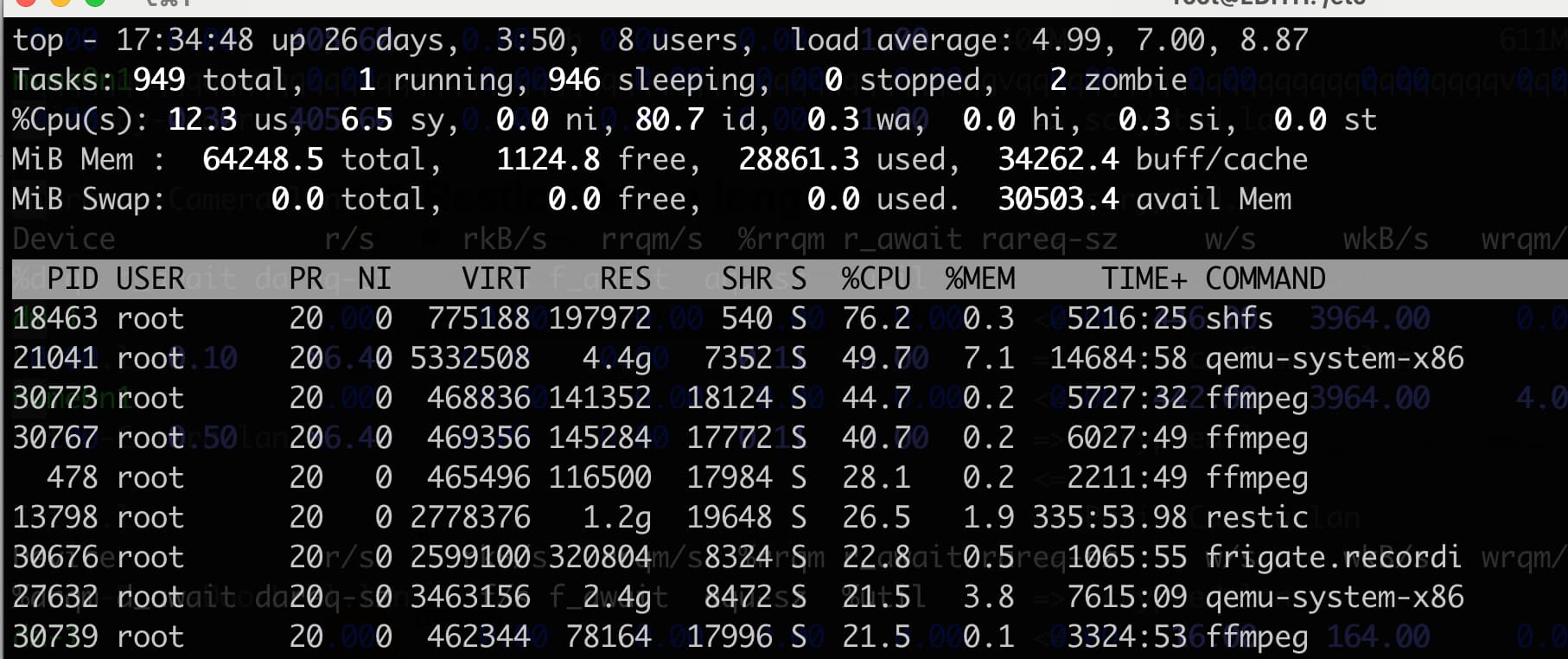
What’s CPU usage on source and target while backing up (top, also get the wa value from top) ?
What’s the bandwidth usage (iftop), and how much bandwidth do you have between your hosts (using iperf) ?
What’s the disk busy status during backup (using iostat -dxzy 1 for example, or nmon, or atop )
I will analyze these tools more in depth as i’m not super familiar with how to use these tools. Htop is one I am “most” familiar and even then I don’t look at the values too much just the processes.
wa value is 0 read this wrong. It seems Primary server is actually close to ~15 and Backup server is about 0 right now.
CPU Load
Both servers the average load of the server is 30% and load on the backup server is about 20%. Primary Server
top
Additional context the directories being backed up shouldn’t haven’t any video files from my cameras. Those are going to a separate drive. The only concern I’d have is my VMs as one of them is Scrypted which is one that also reads my cameras but I’m not sure how much of it it writes to the vdisk it’s on. I’m not if the bandwidth is the issue.
Problem is I think that with freshly mounted directories restic considers all content as “new” and rescans every single file (similarly like discussed here on github). Deduplication magic still applies but it takes significantly longer - simply you are reading all your content every time you run backup on “new” mount.
There were attempt to address it (here ) but AFAIK it is still not “fixed” in restic.
Not 100% sure if it helps in your specific case but for mounted snapshots I started using rustic which supports ignore-devid option.
When you say “freshly mounted directories” are you referring to the fact that UnRAID uses sort of like mergerFS? I think this only happens at boot so i dont know why this would happen here considering the server has still been up. For now I’m excluding the VMs in case those are causing too many reads. But still need to investigate further. I should technically be taking snapshots and backup those instead of copying a running VM.
So far so good, your cpu / bandwidth seem okay, but from what I see:
Are you backing up to a SSHFS file system ? If So, don’t search further, it’s painfully slow, is limited to one CPU core and eats that CPU for encryption. Try migrating to rest-server
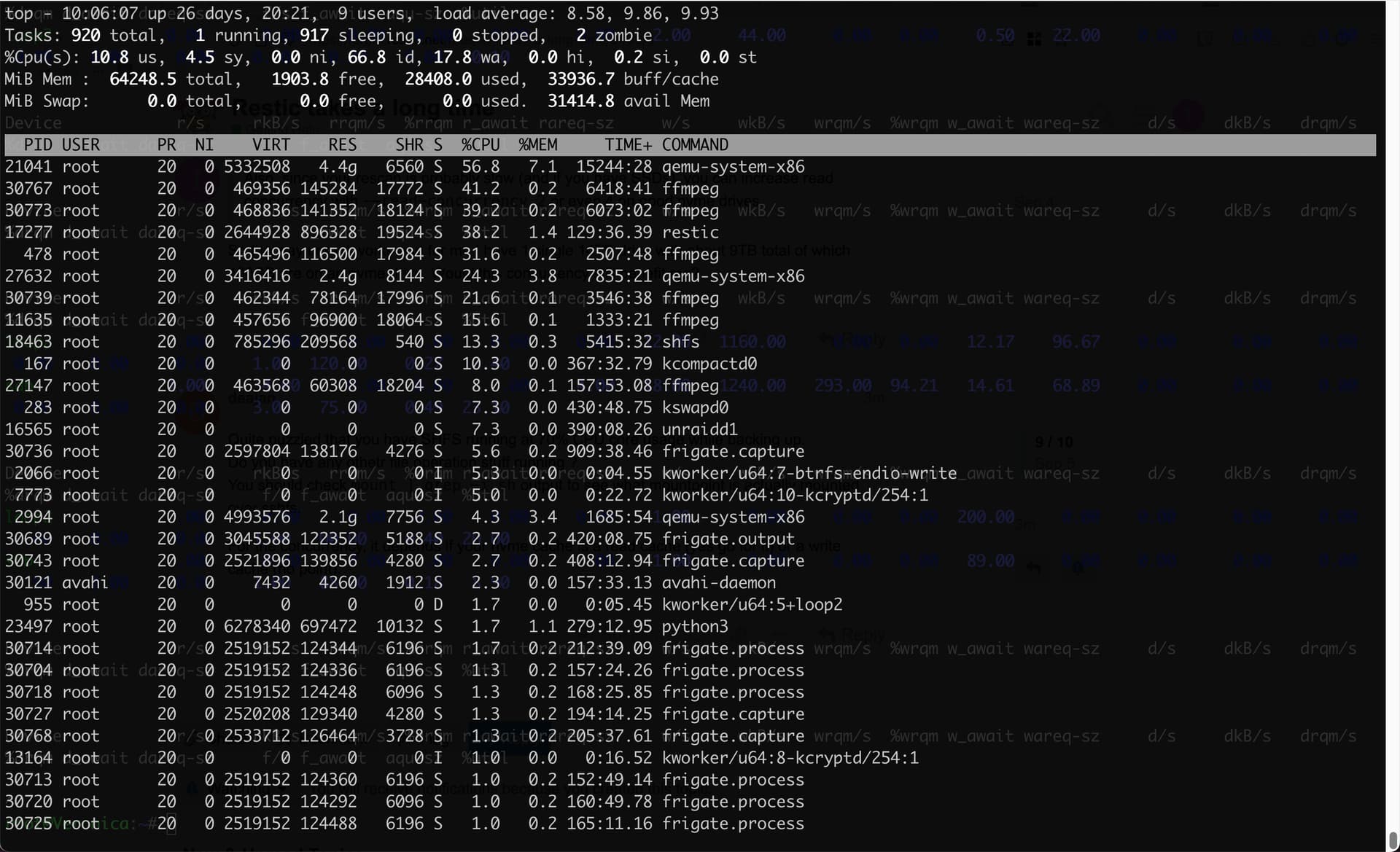
The wa value of the second top screenshot looks high (it’s basically the waiting for IO to complete counter). Can you make a iostat -dxzy 1 on that particular host while backing up ? I’d not be surprised if disk usage is high.
I’m also interested in @kapitainsky 's approach, since it might shed light on something obscure to me.
Indeed, having 8TB to backup, rescanning could be painfully slow.
Would appreciate feedback about said parameter.
Also, since your rescan is probably slow (and if you have SSDs), you can increase read concurrency with --read-concurrency 2 or even 4 on good nvme drives.
Perhaps you should try all of this on a smaller subset of your 8TB, in order to make quicker tests and be able to test all the above.
The wa value of the second top screenshot looks high (it’s basically the waiting for IO to complete counter). Can you make a iostat -dxzy 1 on that particular host while backing up ? I’d not be surprised if disk usage is high.
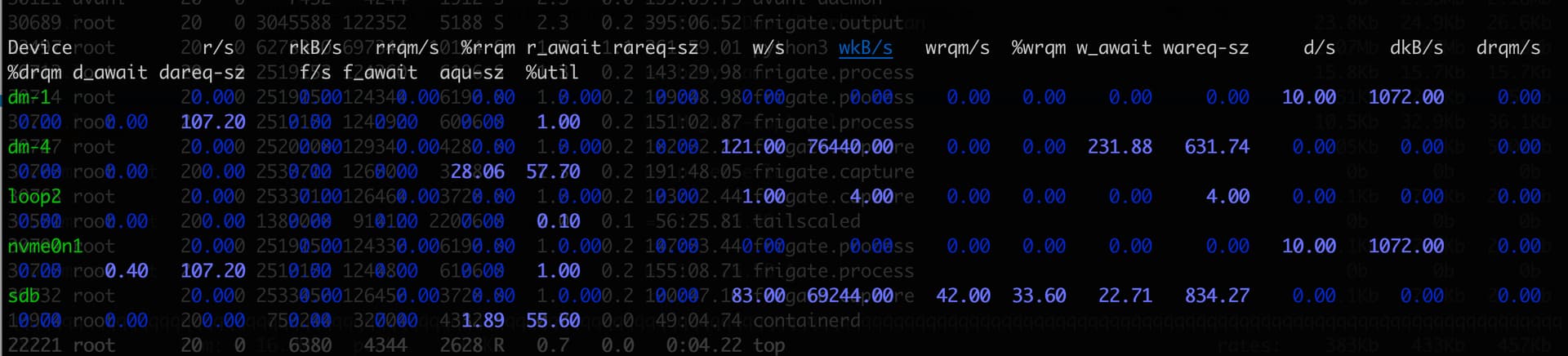
Here is the iostat -dxzy 1
NOTE: I did stop the previous backup and another one started so this screenshot below is for that new one. However, the backup is still going painfully slow.
Put it into chatgpt to give me some understanding of this command.
sdb is the main device to monitor. You have a moderate number of writes happening, and the disk isn’t fully utilized, but w_await and %util indicate it might not be running at its peak performance. This could be worth looking into if your workload is sensitive to disk latency.
Are you backing up to a SSHFS file system ? If So, don’t search further, it’s painfully slow, is limited to one CPU core and eats that CPU for encryption. Try migrating to rest-server
I am actually using rest-server on this backup server.
Also, since your rescan is probably slow (and if you have SSDs), you can increase read concurrency with --read-concurrency 2 or even 4 on good nvme drives.
So the way unraid works and for me I have 1 single 14TB drive with about 9TB total of which 400GB are on an nvme drive. Would this concurrency still benefit me?
Quite puzzled that you have SHFS running at 70% CPU core usage while backing up.
Do you have any othetr file operation stuff running ?
You should check mount | grep -i sh output to see what mountpoint is actually mounted over sshfs.
For the concurrency, it depends if your nvme cache is a read cache (yes go for it) or a write cache (no point).
OK you are right and I didn’t know exactly how unraid did this, but basically unraid does a union filesystem to present a single mount point in /mnt/user path for all my data. This is what I am backing up. When i did the grep under mount it indeed shows that shfs is used under the hood for unraid’s union filesystem.
shfs on /mnt/user type fuse.shfs (rw,nosuid,nodev,noatime,user_id=0,group_id=0,default_permissions,allow_other)
I overlooked your comment here. I didn’t know how unraid did it but it does seem they use shfs under the hood to present all the disk storage in an aggregated mount format under /mnt/user. Its technically what the whole gist of unraid is to show you a single mount point for all your drives regardless of their size.
shfs on /mnt/user type fuse.shfs (rw,nosuid,nodev,noatime,user_id=0,group_id=0,default_permissions,allow_other)
Where the diskN is the actual disk itself. They then join all disk into /mnt/user to present folders that represent samba shares. In my case appdata_vms, cache and disk1 are a single nvme, a pair of SSDs, and a single 14TB drive.
Are you suggesting that I should just use each of these folders: cache and appdata_vms and disk1 when doing my backups to skip the shfs?
TBH, that’s a question to ask on unRaid forums. I don’t use that system so I won’t suggest anything without better knowledge of what that piece of software actually does.
If the tierring they’re doing is just file moving according to some LRU database, than it would be okay.
But if the tiering is more complex (ie bloc related), I’d not touch it with a stick from less than 3 meters unless the FS presents the data without tiering knowledge.
So read this and researched this. Unraid uses a cache drive primarily as a write cache. When you have a single ssd or a set of ssds (in raid 0 like in my case) it functions to have all files written first to there and then late at night it will move everything to the array using a function called “mover”. Basically it is a write cache.