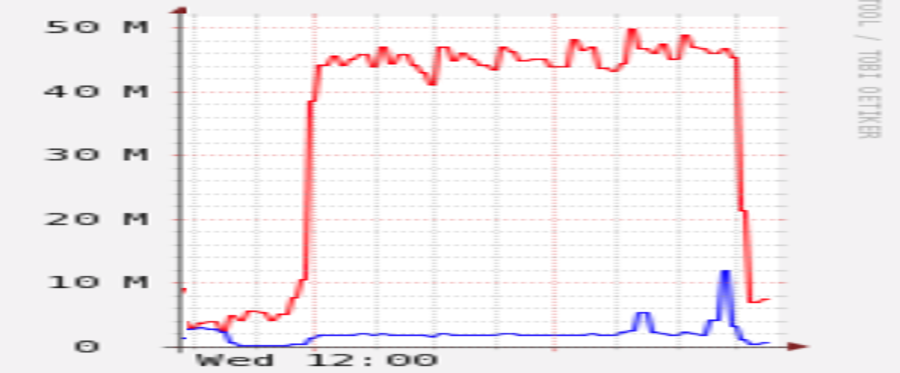
I did, and restic_out-of-order-restore-no-progress worked admirably: I was able to finish the restore in exactly 4h08m, almost topping my available 50Mbps upload bandwidth the whole while:
Great job, @ifedorenko!
Unfortunately, when I verified the restored files (using shasum) I detected that two of them had their contents corrupted; comparing them to their originals held in a ZFS snapshot, I was able to determine that all their metadata (including size and mtime) was exactly the same, but one’s data had 13 bytes changed to apparently random values, while the other had 8 bytes zeroed out.
I don’t think it’s hardware as I’m using good server-class hardware – Xeon processors with ECC RAM on all involved machines, but perhaps it wasn’t restic’s fault either, as I missed making a snapshot of the restored files right after restic restore finished, and the restore target was to a network shared directory where conceivably something else could have messed with it – so I will try and repeat this test on the near future, on a more controlled setting, so as to be able to pinpoint exactly where the corruption was introduced.
When I reach a conclusion on that, I will post an update here.
Cheers,
– Durval.