Hello everyone,
Sorry for the exclamation points, but this is pretty much an emergency.
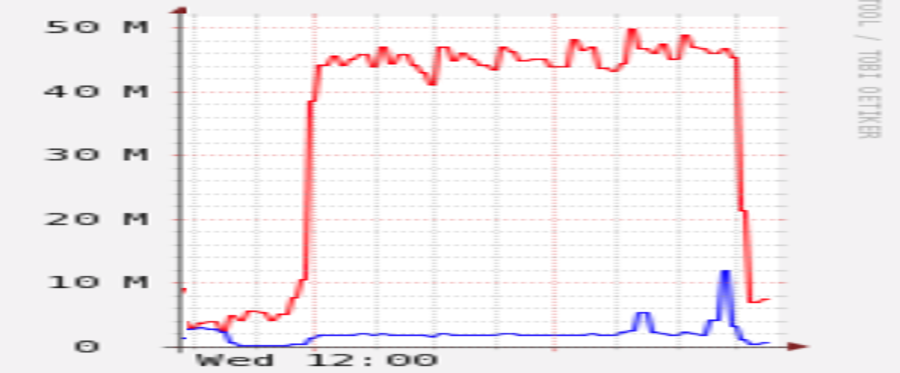
Since yesterday, I’ve been running a restic restore to read back a relatively small (220K files / 72GiB) subdirtree of my 33M files / 23TiB backup, and things started pretty well, but then it started going literally downhill, please see picture:
RIght now, it’s progressing at the amazingly slow rate of 43KB/s – yes, K as in Kilo: less than 0.09% of my available bandwidth, and more importantly, around 1/1000 of the speed when it started. ![]()
What’s worse, a dtruss on the restic process shows it doing a WHOLE LOT of nothing at the system call level: just lots and lots of semwait*() and psynch*() syscalls, see here, which I understand are thread-synchronization fluff; even worser, if I filter those calls out, I can only see a lot of madivise() syscalls (see here) which I understand are Golang’s GC telling the kernel which areas can be considered free.
But, it has not completelly stopped, at least not yet: if I filter specifically for read() calls, I see a precious few of them: only 3 calls returning exactly 4K each (ie 12K bytes) in ~10s, which jibes with what I’m seeing (with df -k) being added to the directory I’m restoring to.
For reference, this is standard restic 0.9.4 compiled with go1.11.4 on darwin/amd64, running on MacOS/X High Sierra in a MacPro Late-2013 Xeon quad-core with 64GB RAM entirely dedicated to running restic (I’m not even logged on its console, everything is being done over SSH). I checked all system logs and see nothing strange. The exact command used for the restore is:
restic --verbose --target=. --include="/LARGEBACKUPROOT/SMALLSUBDIRTREE" restore 706e249a
The current speed is completely untenable: there’s still 32% (17.5GiB of 72GiB) of the backup to restore, but at this rate it would take ~113 hours to finish. ![]() And even if I could/should wait this long. this
And even if I could/should wait this long. this restic restore is using up 38.6GiB (of RSS!) of my 64GB of RAM, and tomorrow night I will need this memory for the restic backup that is scheduled to run.
And this is with a very small subset, measuring ~0.5% of my entire backup: I shudder to think what would happen if I tried to restore the entire set. If this is restic’s ‘normal’ (and I sure hope it is not) it would make restic entirely unfeasible here as its main use would be disaster recovery.
So, my questions are:
-
Is that
restic restorejob beyond hope of ever picking up speed? Or is it best to kill it and start it anew? In that case, any chance of it skipping the 2/3 it has already restored? -
Did I do something wrong in the
restic restorecommand-line above? Could I somehow do things better / more efficiently? -
Apart from using
restic mount, which I would rather avoid, is there any way out for restoring parts or all of that backup?
Thanks in advance for any help.
– Durval.