Hi there,
I want to backup my data to b2. I initialized a repository, and am currently running
restic -r b2:lasse-backup:/ backup /home/lasse --exclude-file=/home/lasse/excludes.txt.
My exclude file includes multiple lines, one of which is
/home/lasse/.Genymobile.
However, As can be seen in the attached screenshot, the .Genymobile folder is still being backed up. What did I do wrong?
Thanks for your help!
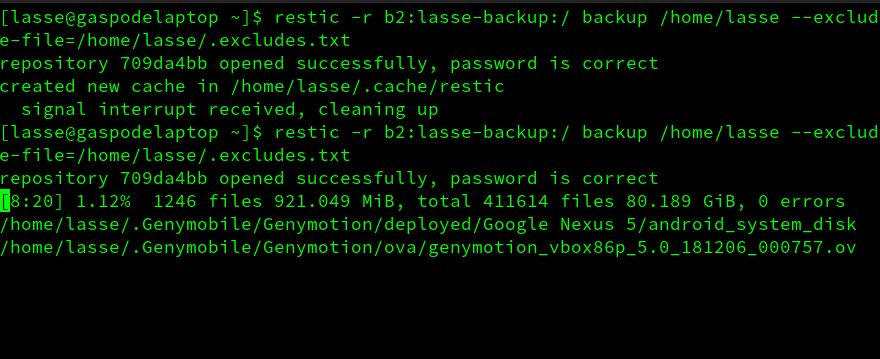
Are the paths in the exclude file supposed to be relative? Since I am backing up /lasse/home should the path in the exclude file be /.Genymobile instead?
Yes, if you’re backing up /home/lasse, then /home/lasse is considered the root directory in your exclude file. Use /.Genymobile in your exclude file.
I just tried it, and it is still backing up the folder. I have learnt that du uses the same syntax as restic, I will play around with du until I get it right and then report back.
Just to be clear: I am backing up /home/lasse, want /home/lasse/.Genymobile excluded, and in my exclude file I now tried /home/lasse/.Genymobile as well as /.Genymobile. Neither worked.
I am also excluding folders such as /home/lasse/.cache so just adding .cache wouldn’t work as this would also exclude subfolders of different directories that are named .cache, if I understand correctly.
1 Like
Ok so with du it works if I include relative paths, so ./.Genymobile would work. I’ll try with restic now.
That’s not correct, quoting Backing up — restic 0.16.3 documentation
Patterns are tested against the full path of a file/dir to be saved, even if restic is passed a relative path to save.
So the exclude pattern should either be /home/lasse/.Genymobile or .Genymobile. The latter case will exclude all files and dirs calls .Genymobile in the directories.
I don’t see a reason why it should not work. Can you please try to pass the exclude pattern on the command line? Like this:
restic -r b2:lasse-backup:/ backup --exclude "/home/lasse/.Genymobile" /home/lasse
Does maybe the exclude file have odd line endings or so?
1 Like
I am currently backing up to backblaze b2 using relative paths, I will try again on a repo in my local network tonight with the absolute paths tonight and let you know. I am using restic 0.9.6 compiled with go1.13.4 on linux/amd64. Line endings should be normal, I just created a txt file using gedit (Gnome text editor). Also, it now seems to work (using the relative paths for the excludes) and I did not change the line endings.
Hi there, I tried to reproduce my problem but wasn’t able to, so I guess I must’ve just made a mistake earlier. Here’s what I did to reproduce, which worked (didn’t reproduce the issue):
Create folders and files:
/tmp/test/test1/testfile1
/tmp/test/test2/testfile2
echo "/tmp/test/test2" > exclude.txt
restic -r /tmp/testrepo backup /tmp/test --exclude-file=/tmp/exclude.txt
This worked and excluded test2 and testfile2 as expected.
1 Like
Oh… you’re right of course. I confused my rclone exclude file with restic.
1 Like
I noticed a different flaw though: When resuming a backup, the ETA is completely off. It seems that it just calculates time_spent/gigabyte_done and extrapolates that for the remaining data as ETA, but it should ignore the data that has already been uploaded earlier for the calculation of the ETA, since that data completes way faster.
But restic doesn’t necessarily know the data is the same until restic processes it. ![]()
Think of the ETA as a worst-case scenario – what would be required to upload everything without deduplication.
1 Like
I think you misunderstood what I meant. When I am resuming a backup (no snapshot created yet), and I have already uploaded half of what needs to be uploaded (say 50GB), restic will quickly go over that first half (say in 50 seconds). It will then take that speed to estimate the ETA, and show that the backup will be done in 50 more seconds. In reality, the second 50GB will take way longer, since they have to be uploaded. So the ETA is more of a (unrealistic) best case here.
I see. In that case, restic still doesn’t really know how long it all will take since it can’t know that future data won’t be deduplicated. Asking it to disregard prior data that was deduplicated could just as easily lead to others reporting the issue I thought you were initially raising: the estimated time is way too long since most of the data is deduplicated (estimating hours for a backup that will complete in minutes).
The estimate is just that: an estimate based on the information restic has available. If there’s an algorithm you can propose that will be more accurate in all cases, I’m sure @fd0 would be willing to take a look at it.
Not to mention that other factors can affect the time it takes in the end. The best any software can do is make a guess based on some current timeframe of performance. Any second later throughput could drop or increase substantially, regardless of what estimate you make at any given point in time.