This is both an idea and something I’m attempting at the moment…
I had a Restic database stored in a Dropbox folder - but I let Dropbox handle the syncing. That was, to say the least, a mistake - but rclone was getting limited to about 1-2MB/s and it was unusable through that backend. So I thought I’d be “clever” and store the Dropbox on an external volume, and let Dropbox the app handle the syncing. It worked… until it didn’t. I moved the external volume to a new computer, and re-setup Dropbox. It probably would have worked if they were already in sync. They weren’t, though. The cloud copy was out of date. Well, when I re-setup Dropbox, it took the cloud data as the most recent, and started deleting things but also adding the new snapshots. Then it ran out of space. So now I have a very mangled database. Luckily it’s all backups of backups, and nothing important was lost. This was always just a failsafe. All my users have their own Time Machine volumes.
Anyway,I created a new database on SharePoint and have been using that instead. I had given up on the Dropbox repository. But I just had an idea. What would happen if I did a “copy” operation from the broken repository to the new?
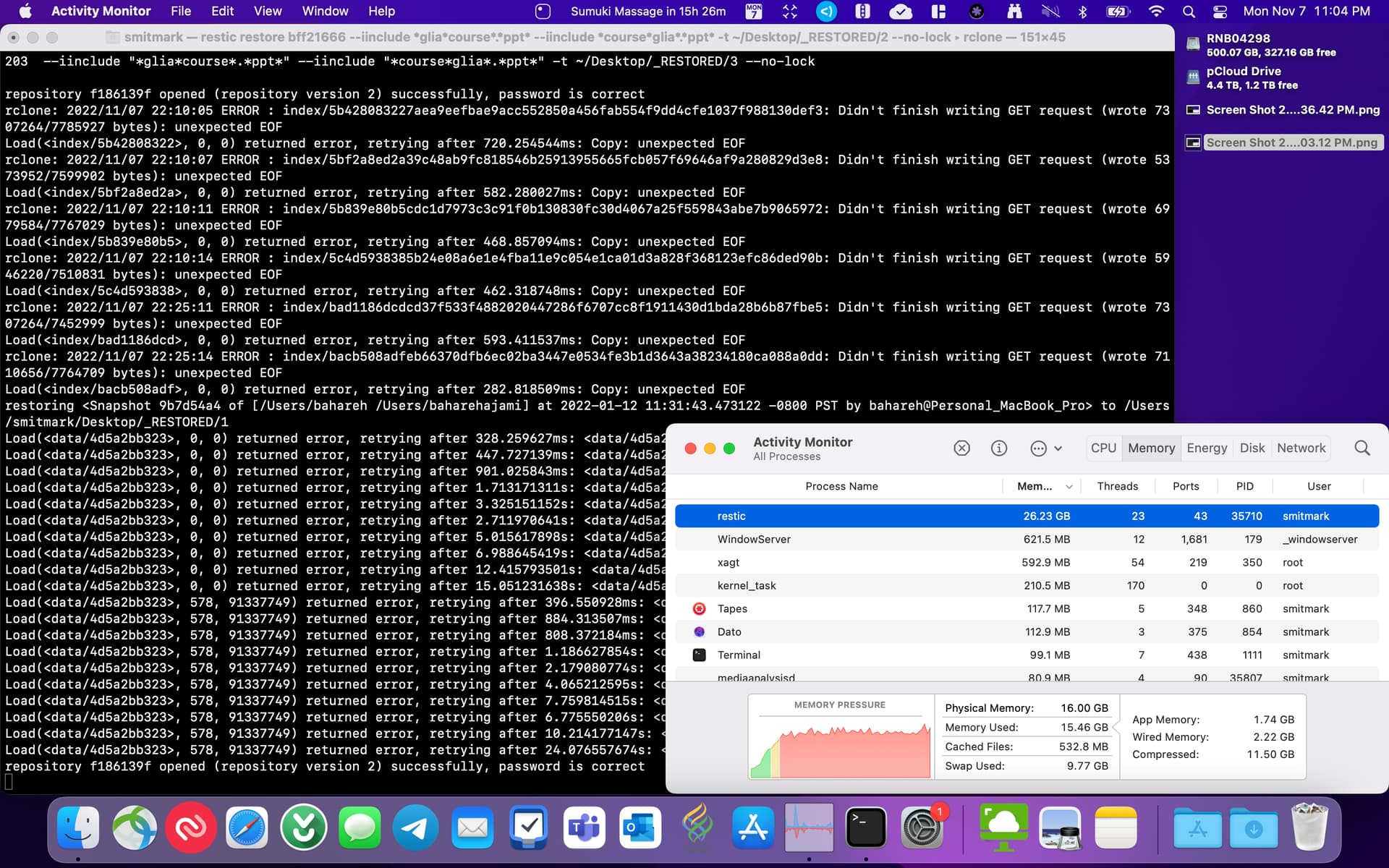
Well pretty quickly, I started getting a ton of these:
Load(<data/2ae013c2b9>, 0, 0) returned error, retrying after 728.983862ms: <data/2ae013c2b9> does not exist
My idea is… what if there was a --skip-missing or --skip-damaged switch, that upon “restic copy” encountering missing data, it would just skip that snapshot and try copying the next? That way if there are any salvageable snapshots, you’d be able to recover them? Just a thought!
So trying “restic copy” actually caused restic to full-on crash.
I think I’ll just try copying each snapshot individually. That way if it crashes it’ll keep going on the rest. I did manage to recover a few this way already, though!
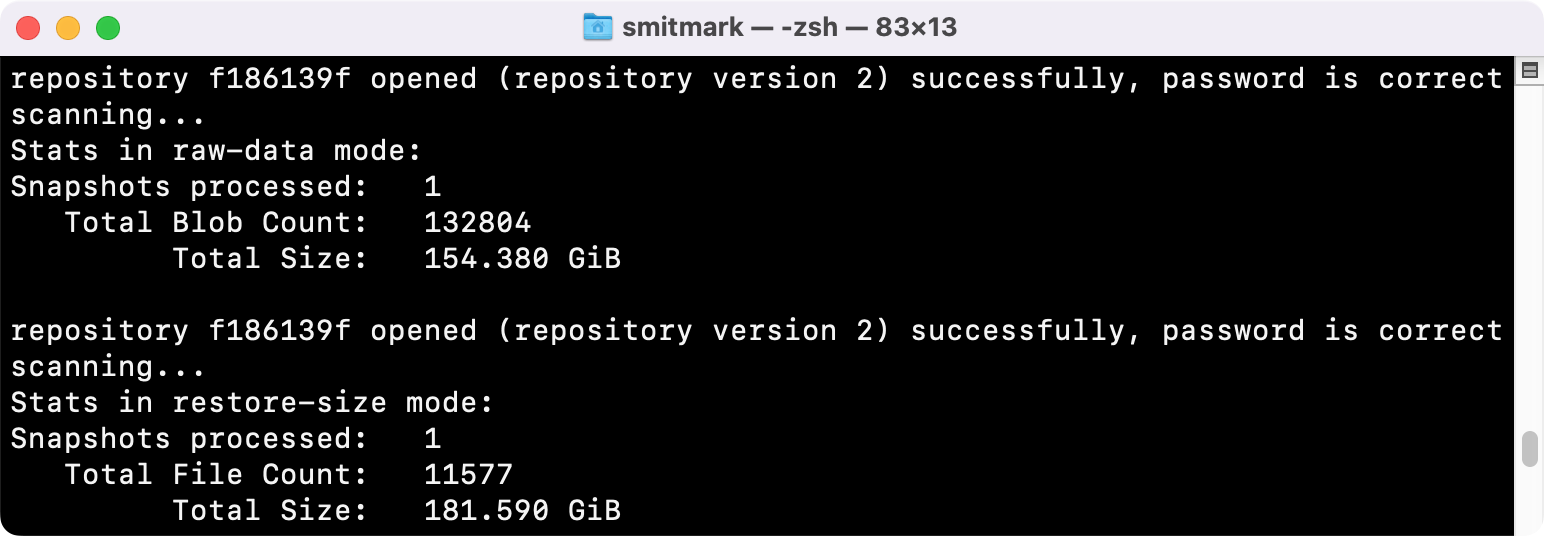
So I originally had 3.4TB of raw data. Since Dropbox can’t “roll back” to a date, I was forced to restore ALL deleted files. This ballooned my repository to 6.7TB. I then couldn’t operate on it in the cloud, so I had to sync it down to an 8TB RAID-5 set. With that complete, I was able to rebuild-index and run the repair. It worked! I only lost 5 out of 333 snapshots.
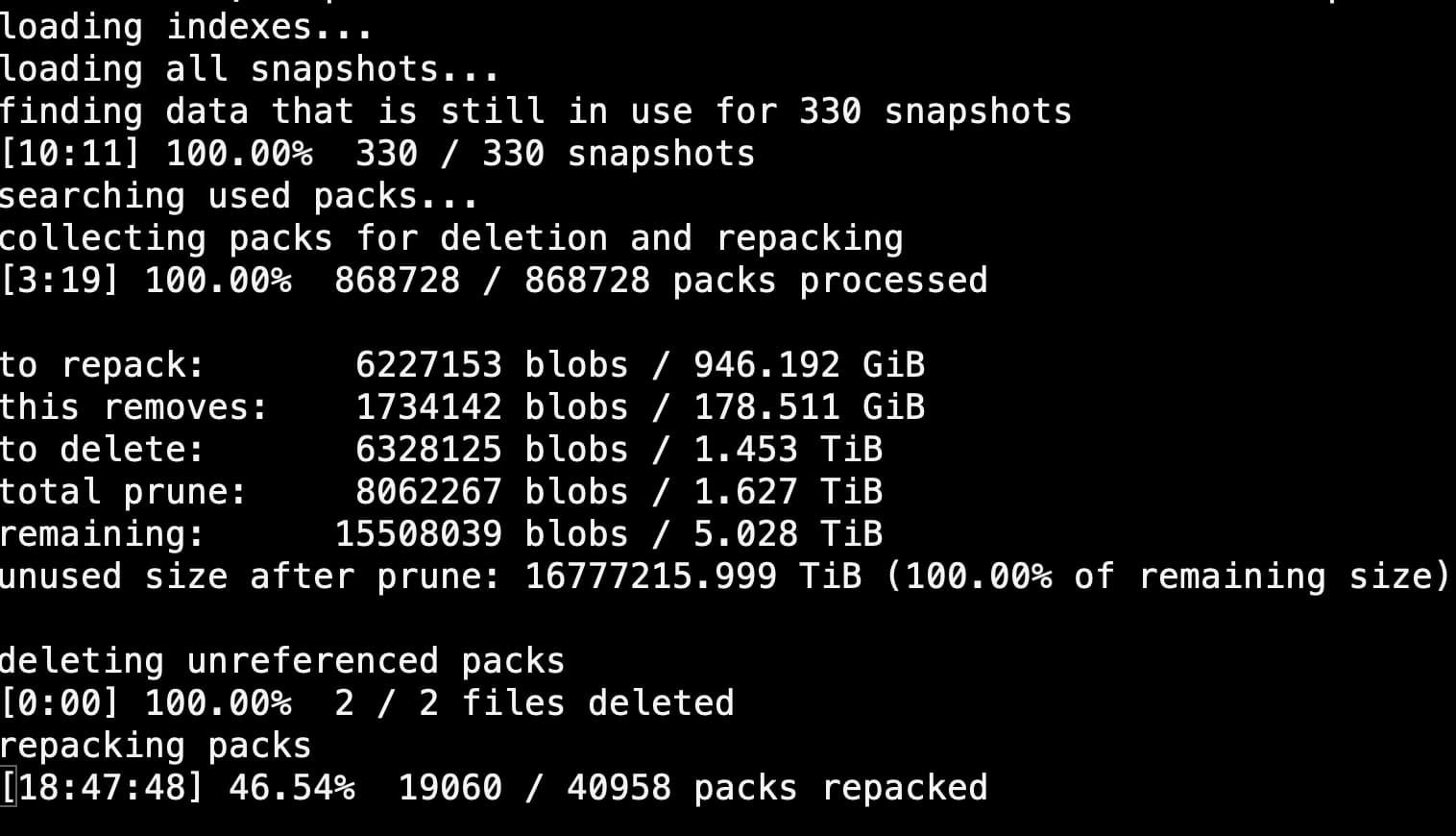
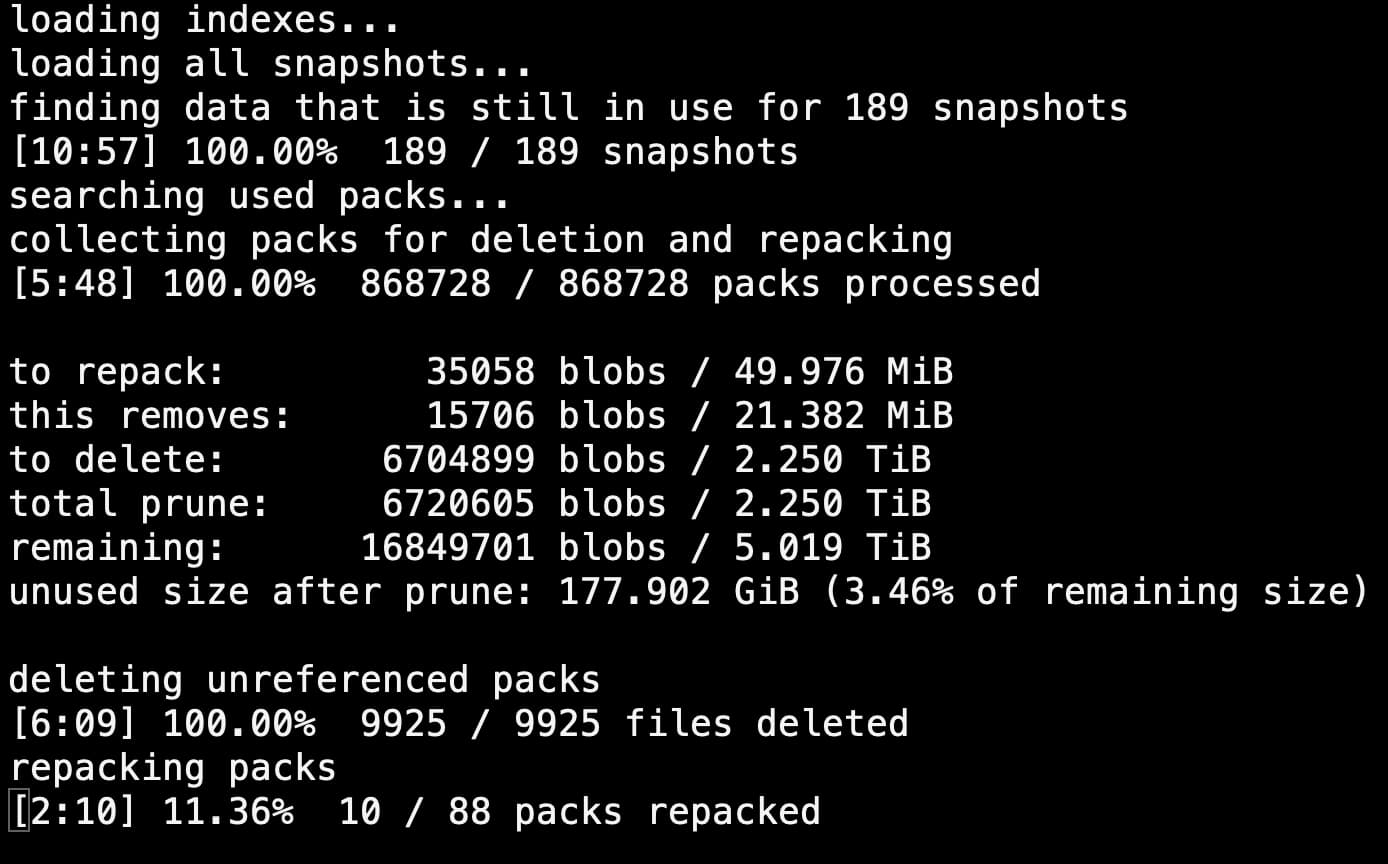
But, speaking of “a bit excessive”… how’s this prune run look to you? haha
Apparently it was serious about the 16777215.999 TiB - at least it filled up the 8TB RAID-5 array. I deleted the “repaired” snapshots, correctly suspecting them as the issue, then ran prune with --max-repack-size 50M. That got things down to a more manageable 5TB.
Hmm I only used the PR to repair. I’m using 0.14.0 to prune. I’m guessing it hasn’t made it to stable yet though. I’ll try one of the beta builds if I run into any actual trouble with it. Thanks!