We’re proud to announce that restic 0.12.0 has been released today! This release packs many speed improvements in several restic commands. For example, we expect that the garbage collection process (restic prune) will be an order of magnitude faster for almost all users. In addition, you can now configure how much data should be optimized (via --max-repack-size) and how much unused data is allowed to remain in the repo (via --max-unused). These flags gives you more control over how long restic prune will take overall, and also allow you to have several shorter runs of restic prune instead of a single long one. A special thanks goes out to Alexander Weiss for these indeed awesome improvements in particular, but also to all the other contributors who work on restic!
The new prune performance is amazing. This makes a massive difference with my backups and I’ll have to review my backup strategy now that prunes are quick.
I do have a question regarding the --max-unused option. What is the default value for this, if it is not specified by the user?
Very nice thank you. One of the backups I run does a weekly prune. The time goes from 14 hours to 25 minutes.
Here is a chunk of last week’s:
counting files in repo
building new index for repo
[7:25:03] 100.00% 1067848 / 1067848 packs
repository contains 1067848 packs (4087719 blobs) with 5.194 TiB
processed 4087719 blobs: 30 duplicate blobs, 4.555 MiB duplicate
load all snapshots
find data that is still in use for 14 snapshots
[0:40] 100.00% 14 / 14 snapshots
found 4087575 of 4087719 data blobs still in use, removing 144 blobs
will remove 0 invalid files
will delete 10 packs and rewrite 4 packs, this frees 6.397 MiB
[0:03] 100.00% 4 / 4 packs rewritten
counting files in repo
[6:21:35] 100.00% 1067836 / 1067836 packs
And here is this week’s which did a similar amount of work:
7 snapshots have been removed, running prune
loading indexes...
loading all snapshots...
finding data that is still in use for 14 snapshots
[0:18] 100.00% 14 / 14 snapshots
searching used packs...
collecting packs for deletion and repacking
[20:34] 100.00% 1070475 / 1070475 packs processed
to repack: 14 blobs / 283.643 KiB
this removes 12 blobs / 184.887 KiB
to delete: 57 blobs / 1009.983 KiB
total prune: 69 blobs / 1.167 MiB
remaining: 3946267 blobs / 5.208 TiB
unused size after prune: 102.098 KiB (0.00% of remaining size)
repacking packs
[0:00] 100.00% 1 / 1 packs repacked
rebuilding index
[3:30] 100.00% 1070469 / 1070469 packs processed
deleting obsolete index files
[0:02] 100.00% 370 / 370 files deleted
removing 7 old packs
[0:00] 100.00% 7 / 7 files deleted
done
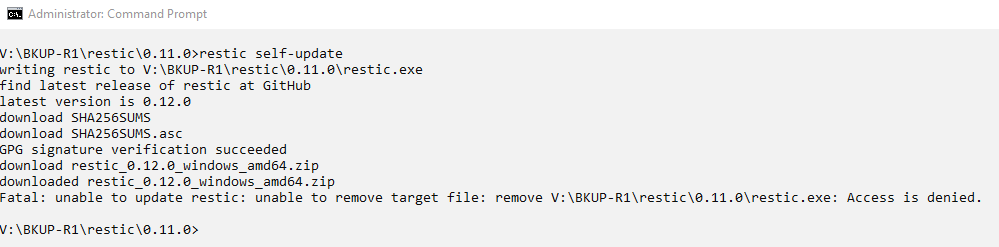
That’s a known issue, restic is not able to replace itself while it is running. You can use --output restic-new.exe to write the downloaded program into a new file and then move it to the destination afterwards.
Just echoing that the new prune is fantastic. The lower memory footprint really helps on our backup server, which has a ton of disk space but not a whole lot of RAM (we didn’t use restic when we originally set it up, it was just a dumb sftp server). The past 6 months or so I’ve been running the rest server with an SSH tunnel to my workstation and running restic there, where I have plenty of memory. Even with the additional latency, this was substantially faster than running restic on the backup server itself, and also a lot more reliable – it wasn’t uncommon for pruning to cause swap death on the backup server.
With this new version, we can prune the same repositories directly on the backup server again, in a matter of ~10 minutes, and swap is barely touched. Kudos to those who developed the new prune implementation.
The CHANGELOG.md file is useful. I can only speak for myself to say that having it ordered numerically is not useful. The change number does not mean anything to me as a user of restic. Perhaps ordered by subject, which would be subjective, such as:
Bug Fixes,
New Functionality,
Performance Improvements
Other
Another criteria which would help me read the changes is to separate changes which deal with specific hardware or operating system. I am on Windows and backup only to a locally connected usb drive so all of the changes to how restic interfaces to various cloud storage does not matter to me. It does matter to others so if a subject title listed those items I would read more thoroughly the items which pertain to my use of restic. Resic is wonderful and the people in the restic forum are wonderful.
Thanks.
This is how it is now - the entires in the changelog are grouped by type of change, e.g. Bugfix, Enhancement, etc. See the summary list at the top of it. Within those groups, the changes are ordered by issue/PR number.
I understand that this might be helpful. I’m not sure it would be worth the additional effort though. As it is now, we already have to do extra work to make sure that the changelog entries are in shape and formatted properly to be included in the changelog. Having to also determine what categories to have in the changelog and then categorize/label entries, it wouldn’t be a small task. I agree it would be useful, but it doesn’t strike me as useful enough to warrant the additional work that would be needed to make sure the label is consistent and applied properly.
Considering what AWS S3 charges to download your data compared with the cost of storing it, I think overall costs would be reduced by increasing the --max-unused setting on prune to about 50%
I have about 50G stored in S3 via restic, so I get charged about 2.3 cents /Gb/month for storage, but 9 cents /Gb to download my data. I currently run forget & prune weekly to manage the number of snapshots, and it is noticeable that the total AWS S3 charges for the day of the prune is about double that compared with other days in the week.
My plan with the new version of prune, is to still run it weekly with --max-unused on 50%, and then once a quarter, do a run with it set to zero to fully repack & remove data for files I don’t have any more.
The performance of the new prune & forget implementation in 0.12.0 is stunning in my setups too. I backup daily & do a forget + prune weekly, reducing the backups to the latest 7 snapshots. Even with smaller backup sizes, the speed improvement is amazing.
On average, I saw speedups in order of magnitude between 6x and 7,5x faster with files that change significantly (e.g. on several single InterSystems database files between 15 GB and 80 GB) and 50x faster (a MailStore database of 500 GB where a small percentage of the files change in one week).
Alternatively, consider running restic in AWS on an EC2, or using Fargate with a suitably-configured container image. A few minutes of compute time is going to be substantially cheaper than data egress.
EC2 instances are billed by the second and there is no minimum. Depending on the repository size, a t3.small instance (2GB RAM) should be fine. This instance costs $0.0208 per hour currently; if prune takes 10 minutes then you’re looking at about $0.004 in charges provided you terminate the instance when you’re done. This could all be automated with a Lambda function that runs an EC2 with user data (a launch script) that will run restic and shut itself down when complete, and the Lambda could be triggered by a timed CloudWatch event to run daily, weekly, whatever.
As an aside, it could be even be possible to run restic inside of a Lambda function, which would be a lot easier than managing an EC2’s lifecycle. However, the max execution time of a Lambda function is 15 minutes so this wouldn’t work on huge repositories requiring more time to prune.
I had thought of doing the restic forget & prune inside an EC2, Fargate or Lambda instance, and you are correct, as the compute cost of doing so would be much less than the transfer out costs from S3.
The reason I am not doing that is, the same reason that I am not storing my backups in the clear. I want my backups to be private, and if I run the forget & prune inside any part of Amazon’s infrastructure then I have to upload my encryption keys to their cloud and my data is no longer private from them, or any lawful or other access requests that they might receive.
I know this comment is a few months old, but you might be able to drop your costs by switching to something like BackBlaze B2. It’s 0.5 cents per GB, instead of 2.3 cents for storage. Downloads are cheaper as well at 1 cent per GB vs 5 cents per GB.
I’m also backing up about 50GB, and my monthly costs are so low I feel bad for B2. I’m under $2 dollars for the year so far…
If you want a deep dive into Backblaze, check out their blog. A lot of the more recent stuff is PR fluff, but farther back they talk about a lot of the systems they use. I actually started following them for the blog posts, long before I started using them to store stuff!
In short though, they built their entire hardware and software stack in house. Only recently have they started buying hardware from the ‘big guys’. They use cheap commodity drives, with redundancy to deal with failures. The software is relatively simple, mostly avoids bottlenecks by pushing work to the bottom layers of the hardware stack.