I have a NAS machine running Debian stable and Restic 0.11.0. I messed up last week and included a large directory I didn’t want to get backed up, which filled up the ZFS pool I store backups on, then aborted the process. I have around 6mb free on the pool now.
I could use some advice on recovering from the situation.
I thought perhaps the restic forget --prune command (which I run weekly to roll off old backups) would free space, but the process is excruciatingly slow for reasons I don’t understand. Rebuilding the indexes took 53 hours, and after that it got stuck on “find data that is still in use for 194 snapshots”, which was still at 0.00% complete after running for 31 hours (until I killed it). I also see that this process is going to write new data before deleting the old data, so however long it was going to take, it would have failed at the end.
As far as I can tell, I have a couple options:
Install a newer Restic version. It looks like there have been some performance improvements and new features for freeing up space since 0.11.0, so I might be able to free up space this way. I strongly prefer to use the normal packaged software in Debian, so my main question is whether I can use a newer Restic to recover from this situation, then continue using the system’s packaged 0.11.0. If newer versions change the repo format, that won’t be an option.
Add an overlay filesystem to provide scratch space, then forget old backups. This might require a new Restic as well, given the abysmal performance of 0.11.0 doing this.
Find and manually delete the pack(s) created by the errrant backup, then rebuild the repo state.
I’m leaning towards option 3, since it seems both simple and expedient, but I thought it would be a good idea to hear some other opinions before I do something which may be irreversibly catastrophic to my backup repo.
Thanks for the suggestion. I’m running 0.14.0 in a container, with my backup repo bind-mounted into it. I also saw that it recommended using a cache, which I had disabled before.
I’m currently running restic prune --max-repack-size 0, but it’s very slow:
[21:31:11] 5.15% 10 / 194 snapshots
0.11.0 spent 29 hours and made 0.00% progress, so this is an improvement, but still utterly abysmal. This is a 4tb repo on locally-attached (via USB 3.0) storage, and cache is on a USB 3.0 flash drive.
Thankfully, it looks like the performance isn’t linear (which would extrapolate to >2 weeks to complete), but it looks like this process is going to take from 2-4 days. That seems like a really long time.
The machine is an i5-7500T (quadcore) with 20gb RAM.
My last prune is quite a long time ago, but what I’ve noticed about pruning is, that it seems to be bound by the memory speed and/or speed of the device the backup is on. I’m for example running an i7-4790 with 16GB DDR3-RAM and pruning a backup on an external HDD does neither put my CPU nor my RAM under heavy usage. What supports this thesis is that the code itself first loads all Snapshots and then operates on them. If there are many cache misses, the data must be loaded many times from memory and thus it can be very slow. But here my assumption may be wrong.
That looks like there’s a serious performance while traversing the snapshots. The snapshot traversal is by now parallelized enough that it will either saturate the CPU or IO.
With the given repo size I’d expect this progress to take at most an hour.
Does the container have any resource limits set?
Is “flash drive” an USB stick or an SSD/NVME? As the repository is on a local drive, disabling the cache shouldn’t make much of a performance difference.
? Loading the snapshot list is not the problem here. And the snapshot traversal is highly parallelized (except for a corner case with directories with very large metadata, but that doesn’t appear to be relevant here).
It sounds like you’re talking about the processor cache. But that leads to different symptoms. The CPU usage will be high but the program still runs slowly.
I don’t have a good frame of reference, but I certainly would expect it to run faster than it did.
The process completed and my backups are in a good state now, but it took around 29 hours for the whole operation, once I got 0.14.0 running and set up the cache disk.
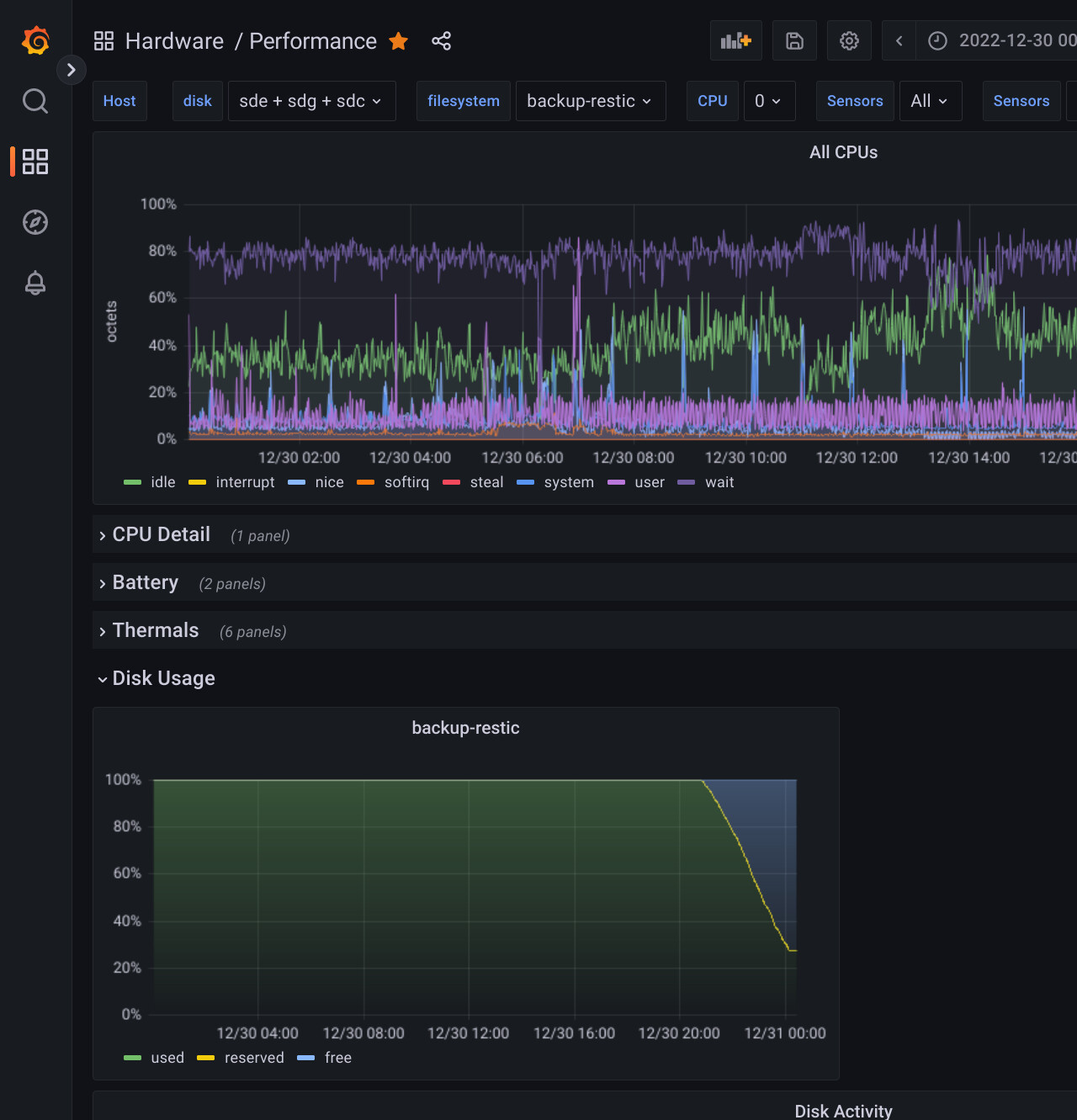
Nothing jumps out at me from the metrics I collected when the prune was running:
sdc is the USB 3 cache disk. sde/sdg are the mirrored zpool which hold the backups. The purple line in the “All CPUs” graph is wait, so it does seem I/O bound, but the graphs of disk activity don’t seem to match that, as the bursts in octets transferred don’t seem to bear any relation to the iowait.
I haven’t set any, I’m not sure if there are defaults or something. I’d assume it has no limits if I haven’t requested any.
I put it on a USB 3 stick. I generally run without a cache on this host, since it holds the complete backup repo locally. I assumed there wouldn’t be much difference using a cache vs. pulling stuff out of the repo in that situation, and it sounds like I’m correct. But given how slow 0.11.0 was with pruning, and how 0.14.0 said it would be slow without a cache, I set up a temporary one to ward off potential issues.