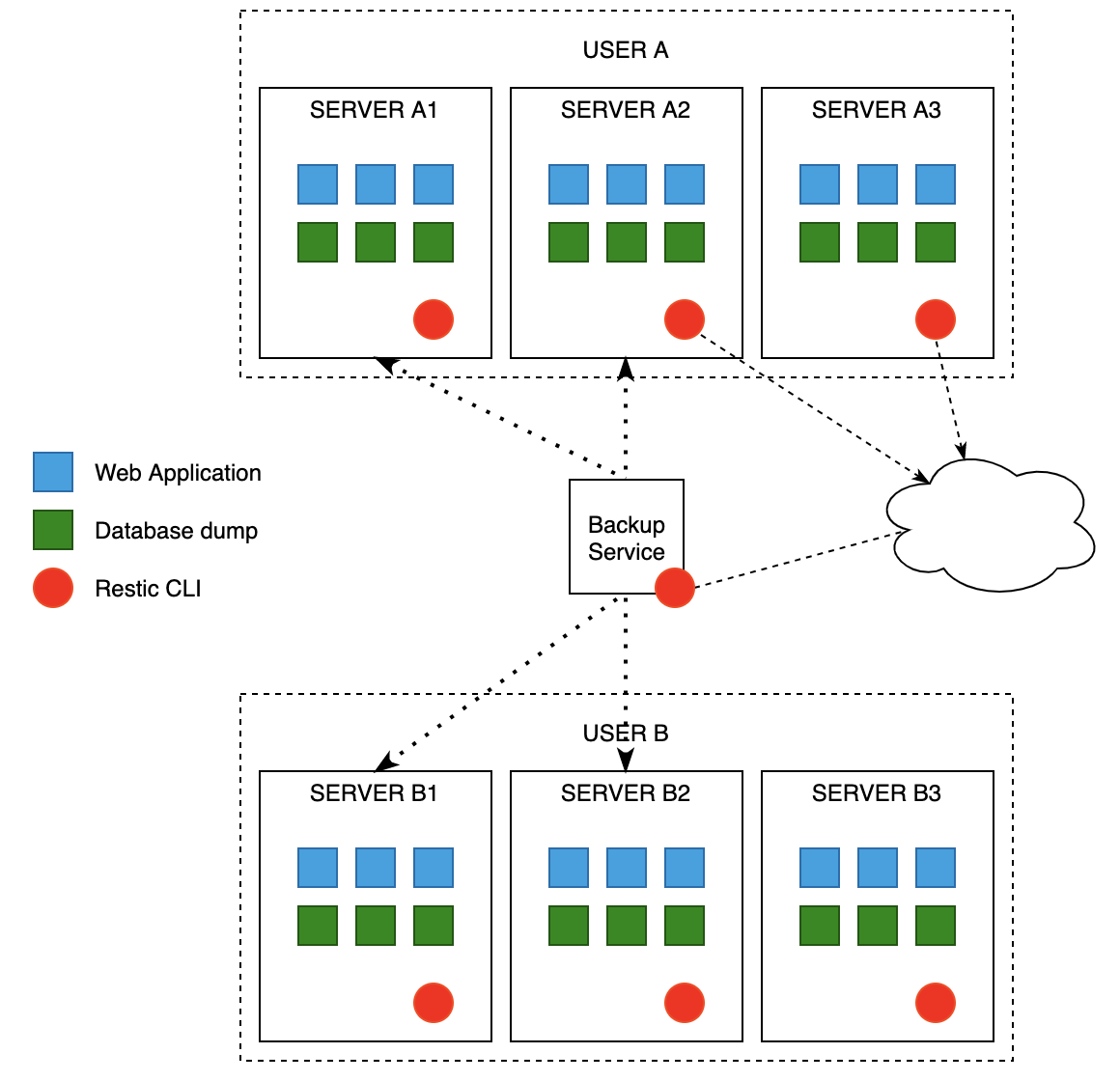
We try to use restic in our existing backup service. But run into problems with many repos, with thousands of snapshots. I would like to get some opinion on how to make this setup right.
We have many users, which can have many servers, which can have many web apps and databases.
One user has one restic repository.
Restic backups web app and database dump in separate snapshots, directly to the cloud storage provider
Backup service manages backup schedule, and backup deletion
Backup service use restic cli as well to get some stats about the backup
Problems
Everything was smooth during development until we deploy to staging. After tested for few weeks, we started to notice few problems with our current setup.
Cache is really crucial to restic. When a repo has thousands of snapshots, to generate cache for the first time, it took a really long time (even if the actual data is small)
Our backup service probably can’t afford to manage cache for all those repositories. There’re tons of them.
Things that make it worse
User can schedule webapp / db backup as frequent as every 30 minutes
We use policy --keep-within 3m to prevent data from early deletion in Wasabi.
Previously, we do experimenting with lambda to offload some heavy operation from backup service, but after having this issue, even lambda will fails.
Appreciate if someone can assist on how to make best use of restic in this scenario.
We’ve recently encountered something which looked like rate limiting for concurrent connections from Wasabi. So far I didn’t investigate further as it happened only a few times.
Contacting Wasabi’s support might be worth a shot if you haven’t done so already.
In my case, the slowness of downloading the cache files of thousands of snapshot/indexes happened for S3 as well.
About the wasabi rate limit. I’m not too sure about that. But yes, I’m also have one case where is does slower than other provider, which is stats --mode raw-data. However by removing the mode, it become significantly faster.
I guess the main issue you have is about too many snapshots, right?
Restic is not that efficient if you have a real large number of snapshots, as each snapshot is saved in a single file in the storage backend.
I didn’t fully get why it is not possible for you to provide a fast storage to be used for the cache, which most likely would be the best solution for your case…
Note that there is no need to keep snapshots for early deletion reasons. Snapshot files are about a few hundred bytes, so there should be neglectable costs. It only depends about pruning were relevant amount of data is removed.
In general, I would not keep snapshots just because of a pricing topic, but those which are really needed. Moreover, if I read it correctly, early deletion does not impose extra costs, but just the costs that would apply if you would keep the file for exact 90 days. So you might ask yourself the question why should you keep data you probably won’t need if this causes technical trouble and costs the same as to delete the data…
Anyway, you could also consider playing around with the new options for prune which are available in the latest betas.
If too many index files are an issue, you can run rebuild-index regularly. This command also got enormous speed improvements if you use one of the latest beta versions.
It only depends about pruning were relevant amount of data is removed.
We do something like forget --keep-within 3m --prune monthly.
early deletion does not impose extra costs, but just the costs that would apply if you would keep the file for exact 90 days
Well sir, you are correct. We misunderstood their pricing before, thought their Timed Deleted Storage cost more. So then, we don’t need to keep the data for whole 3 months, and this will reduce the number of snapshots greatly. Awesome, thanks.
Running rebuild-index seems like a good choice too to reduce the indexes generated. For now we are doing prune (which does rebuild as well) monthly. I’ll see if we need to rebuild more frequent than this.
Well then, that’s reduced to only one problem now.
How to manage caches from tons of repository (thousands), accessible from multiple servers (our backup service has replicas), and optionally from lambda as well.
One quick solution in my mind was to use NFS (EFS), which can be shared across all. But not sure if this is the best approach?
Thanks
Edited
NFS might not be the best solution. I’ll use block storage with a larger server instead.
Seems like you are correct. I just tried this out on a repository at Wasabi with 5k snapshots. Listing snapshots took 3.3sec with a up-to-date cache and 3min 40sec without a cache.