Michael:
I’m currently rather hesitant to add anything further to the roadmap for now. There’s already enough queued for 0.18 to probably require two releases and 0.19 also has the chance to spiral out of control.
Understandably, there is jostling to have one’s own feature requests added to the front of the queue of work being proposed. An unenviable position, having to make prioritisation decisions.![]()
What follows is an argument to prioritise a particular issue that I have been advocating to be addressed for some time. I propose, that if added to the 0.18 roadmap, not only would it help solve 3 existing items in the 0.18 roadmap (as given below), but also lay the groundwork for resolving a long-standing underlying issue that makes restic more difficult to use than it need be - its tight coupling with absolute paths.
- Option to create cumulative snapshots
- limited variant of --strip-prefix
- Option to add description to snapshot
So what’s the Issue?
Back in 2018, fd0 asked an important question:
fd0:
… it surprised me that backing up the same data, to the same destination, but from a different path, didn’t use the a parent snapshot (and no using parent snapshot abc… was printed. Actually, when the backup finished, it printed two separate lists of snapshots…
I can understand why it’s unexpected for you as a user. For me as a developer, I need to ask (honest question): How would restic detect that the files which were previously located in /original/path/mydata are the same that are now mounted at /usbdisk/mydata? Sure, we could try matching the file names and sizes and inodes and device IDs, but all that is only approximate and not exact. Therefore, at the moment, we err on the side of caution and always read data that we’re not sure where it comes from. That’s what users can (and should) expect from a backup program: Saving the correct data
We’ve had several reports now with users reporting their surprise and non-understanding of why restic re-reads the files. Do you have any idea on how to improve this situation from a user’s point of view?
I do. Specifically, my idea aims to:
-
Reduce confusion for users by changing the current, and nebulous conceptual model of Restic backup snapshots;
-
Make Restic more reliably match --parent snapshots;
-
Make all backups relative to one or more defined paths (or ‘/’ by default as currently hard-coded) on command line like other popular backup tools (reducing confusion between absolute & relative backups); and,
-
Make it easier to support backups of removable media, and mounted file system snapshots (LVM, ZFS, etc) without fudging paths and/or complicated chroot set ups
What’s the new conceptual model?
There are three dimensions to every backup snapshot:
-
Where it was taken (host);
-
When it was taken (time); and,
-
What was taken (path/s).
Except, the path or paths can change between snapshots, and unlike the host, and time, cannot be overridden at backup time. The new model would represent the three dimensions of every backup snapshot as:
-
Where it was taken (host);
-
When it was taken (time); and,
-
What was taken (Backup Set Name).
To achieve this, my idea proposes two changes:
- Explicitly name each backup snapshot that is taken, with all snapshots sharing the same name on the same host being defined as a “Backup Set”, rather than implicitly through the absolute path/s on the host computer. This user-chosen Backup Set Name defines what is backed up, rather than the absolute path/s.
Explicitly defining the ‘what’ with a user chosen name, means path/s can change, and restic will still know which parent to use.
And because the absolute paths would no longer be required to identify the parent, the second change comes into play:
- All backup snapshots are relative. They can remain relative to ‘/’ as they are now, but can also be relative to the source paths that are given, much like is typical of existing backup utilities such as
tar, using its-Csemantics. Thus, you construct your own arbitrary filesystem structure in your backup snapshot, rather than it being tethered to/, including Windows (i.e./c:/path)
What about tags?
While restic supports tags, I do not consider them in the three-dimension model. This is because every snapshot has a time, a host, and path. However, a snapshot can have many tags, one tag, or no tags associated with them. Thus, tags are not “exact” enough to assist with identifying parent snapshots. In the above model, consider tags as ‘pointers’ to one or more snapshots - a means of grouping snapshots together, arbitrarily or otherwise, and only optionally.
The proposed new conceptual model
The following diagram of a restic repository attempts to illustrate these three dimensions in the new model being proposed. It is thought that a similar diagram in the user documentation would help users understand how their snapshots are logically arranged within a repository, using the three dimension model that we intuitively rely upon.
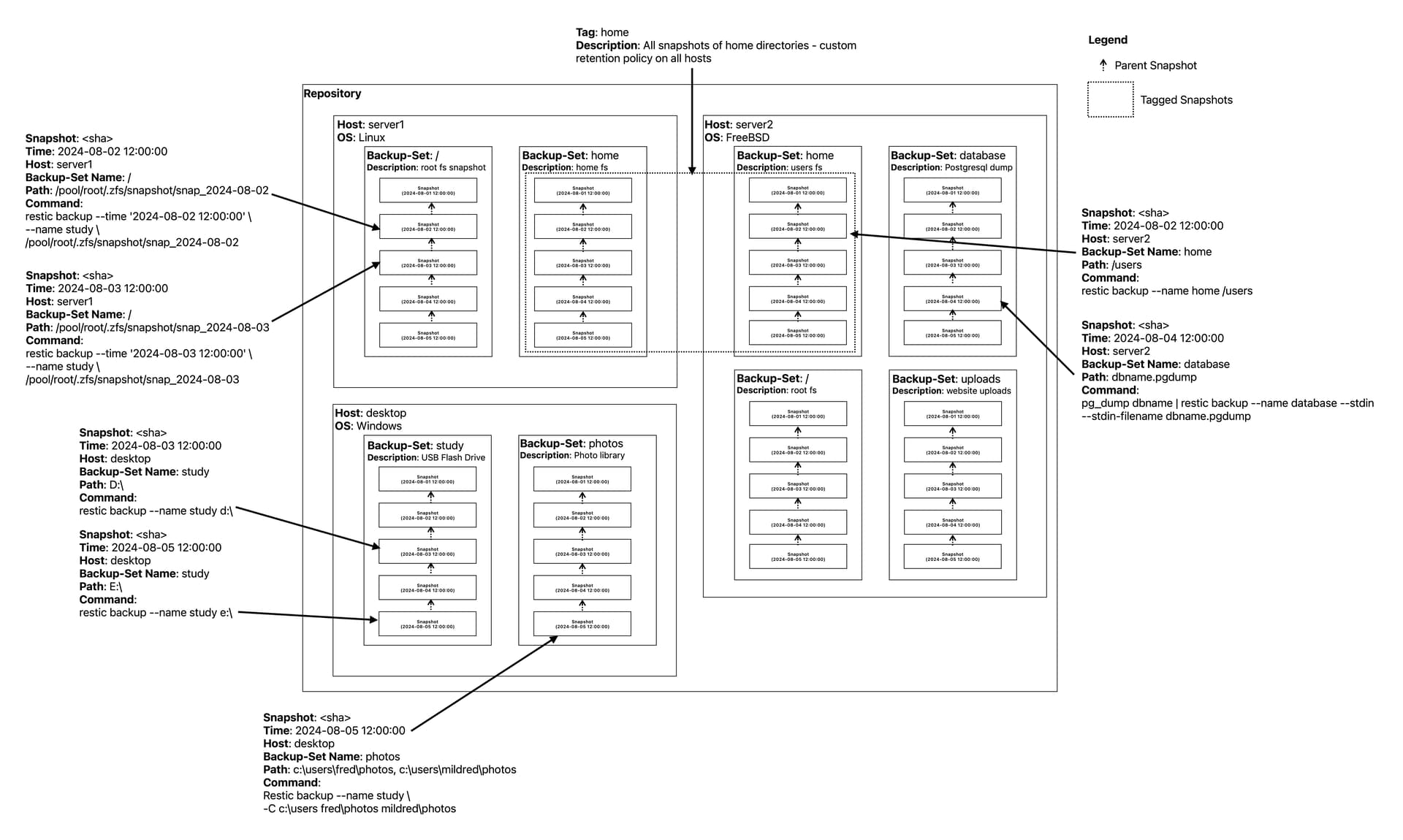
Questions for readers:
- What might your existing restic repository look like using this new model?
- Can you identify all your existing backup-sets, as defined by their one or more paths?
- Can you represent them in a similar diagram, substituting your own where, when & what?
- Does it make the contents of your repository clearer (or not)?
These are sincere questions. Please share the good and the bad - what works and doesn’t.
In essence, a ‘backup-set’ prefigures ‘what’ is being backed up. By defining this backup-set with a name, we can logically and sensibly group together ‘like’ snapshots, even when the path to the files change, and whether tags are used or not.
And we can construct our own internal filesystem structure if and when it makes sense to. Consider the backup-set ‘photos’ on host ‘desktop’ in the example above. Pay attention to the proposed restic backup command, using the -C syntax of tar.
-C c:\users fred\photos mildred\photos
Says make the backup relative to path c:\users and only back up fred\photos and mildred\photos from that relative path, resulting in the following internal snapshot directory structure:
/
├── fred
│ └── photos
│ ├── photo1.jpg
│ ├── photo2.jpg
│ ├── photo3.jpg
│ ├── photo4.jpg
│ └── photo5.jpg
└── mildred
└── photos
├── photo1.jpg
├── photo2.jpg
├── photo3.jpg
├── photo4.jpg
└── photo5.jpg
The path c:\users is not present.
Here are some further example restic commands and proposed syntax that use this new model.
For removable media:
# Unix-like
restic backup -r repo --name 'my external hdd' -C /var/media/<username>/myfiles
# Windows
restic backup -r repo --name 'my external hdd' -C X:\
# MacOS
restic backup -r repo --name 'my external hdd' -C /Volumes/myfiles
For filesystem snapshots:
# Mount all snapshots relate to /mnt/backup/root
mount /dev/vg00/root_snap /mnt/backup/root
mount /dev/vg00/home_snap /mnt/backup/root/home
mount /dev/vg00/var_snap /mnt/backup/root/var
restic backup -r repo --name fullbackup -C /mnt/backup/root
umount -R /mnt/backup/root
# Or mounted separately, and reconstructed using `-C` syntax
mount /dev/vg00/root_snap /mnt/backup/root
mount /dev/vg00/home_snap /mnt/backup/home
mount /dev/vg00/var_snap /mnt/backup/var
# -C /mnt/backup/root will backup everything relative to that path
# -C /mnt/backup home var will backup only directories home and var, but relative to /mnt/backup
# thus, reconstructing the original filesystem mount layout
restic backup -r repo --name rootfs -C /mnt/backup/root -C /mnt/backup home var
The disquisition
For the curious, details can be explored through the disquisition in the following github issue:
Note that ideas evolve throughout the discussion.
Transition
How can such a substantial conceptual change be made smoothly, without requiring users to make immediate adjustments to their scripts and automations?
Presently, parent snapshots are identified by triangulating the the three dimensions of host, time and path/s. For existing snapshots in a repository (and existing working environments under the current paradigm), a normalised representation their path/s (remembering that there can be more than one path for a snapshot), could be declared as the default backup-set name. This means that --name can initially be defined as an optional parameter. If no --name argument is provided (in other words, restic is executed without using the above new syntax), then matching of parents would continue as-is, and thus, will not break any existing automation.
However, if you change paths, you will in-effect, implicitly create a brand new backup-set.
To use the -C function, you would need to specify --name.
This addresses the input interface compatibility layer. What about metadata outputs from restic?
A new output representation (e.g. snapshots command) from restic would thereon refer to backup-sets, rather than paths, where existing snapshots would use the normalised form of the paths as the backup-set name. So the new model would emerge as intended, and over time, users could ‘rename’ their backup sets (a new command) from the existing normalised path/s to a new given name. Then invoke backup snapshots using the new explicit name with the --name argument. Or quote the normalised path as the name, if the path is a good name anyway.
A normalised path might be represented as the sorted concatenation of one or more paths provided to the restic backup command, separated by a comma. An escape character might be needed to represent a literal comma and the literal escape character.
Then a future release could mark the --name argument as mandatory, and simplify the entire restic interface in service of the new model. Every snapshot is named, and matched against existing parents, or if a new name host combination, then it will be flagged as a new backup-set and will perform a full scan without a parent.
Why is this so important?
The user forums are awash with sensible use-cases that require overriding the defaults for each of these three dimensions. Yet, only two are supported: --time, --host, but not the path.
In terms of usability, and in consideration of the broad range of user skills, from novices, to System Administrators, challenges and/or confusion appear again and again in the user forums evidenced through a simple search: Search results for ‘path parent’ - restic forum
-
If i init a specific folder, restic includes the parent paths as well - restic forum
-
Using relative paths - Restore and parent snapshots - Features and Ideas - restic forum
-
Long backup after change of paths (mountpoint) - Getting Help - restic forum
-
Repository broken - id not found in repository - Getting Help - restic forum
-
Expected speed of practically unchanged incremental backups - Getting Help - restic forum
-
Restic slow to snapshot new hard links of large files - Getting Help - restic forum
-
Backup from new machine re-uploads all data - Getting Help - restic forum
-
Confusing/wrong documentation on group-by flag - Features and Ideas - restic forum
-
How does forget work for snapshots with different paths? - Getting Help - restic forum
-
Backfilling snapshots from non-restic archives - restic forum
-
Help: correct use of restic “parent not found” - Getting Help - restic forum
-
Backing up from rclone mount from btrfs snapshots - Getting Help - restic forum
-
Utilizing macOS local APFS snapshots for Restic backups - Getting Help - restic forum
This is a sampling, based on roughly half the results returned from the search - there were more. The earliest sample dates back to the beginning of 2018 circa fd0’s question. The most recent example of confusion was posted only last month:
Parent content identification bug
Clearly, a great deal of time has been spent by community members and developers responding to the inability of restic to cope with data appearing at different paths between backup snapshots, and the complexities of aligning parent snapshots. The evidence to me suggests, this is a high priority issue, and worthy of the 0.18 roadmap.
Next Steps
There is still more detail to flesh out with this approach, and design decisions to make.
A summary of my argument is:
- this work, while substantial, may reduce the number of forum posts from users confused by Restic’s snapshot model, and thus, give valuable time back to the broader community; and,
- it will also solve (or substantially contribute to) three items already listed for the 0.18 roadmap
So, the questions become: is there broad support for exploring this model change further? And if so, as a priority for 0.18?