we have a filesystem with about 500GB of data and 13.5 million files which we create a daily backup of with restic. The files are stored in AWS EFS and we wanted a backup outside of AWS. The restic repository is stored on a StorageBox from Hetzner.
The filesystem stores the files in folders sorted by the first 12bits of their hashes, so there are 4096 folders which each contain about 3300 files and all files are pretty small.
Creating the backup works fine, there is about 1GB of changes everyday and it takes about 5 minutes.
We recently tested restoring from this backup to a fresh AWS EFS with a t3.2xlarge EC2 instance (8 CPU cores, 32G ram) using restic 0.16.4 .
The restore ran with a constant speed until almost everything was restored and then slowed to a crawl and restoring only about one file/dir per minute. After waiting some more hours we aborted the test as it would take a few days at that speed.
When looking at the restored files it looks like restic was in the second pass restoring the metadata as I could watch the directories slowly changing owner, access time, etc.
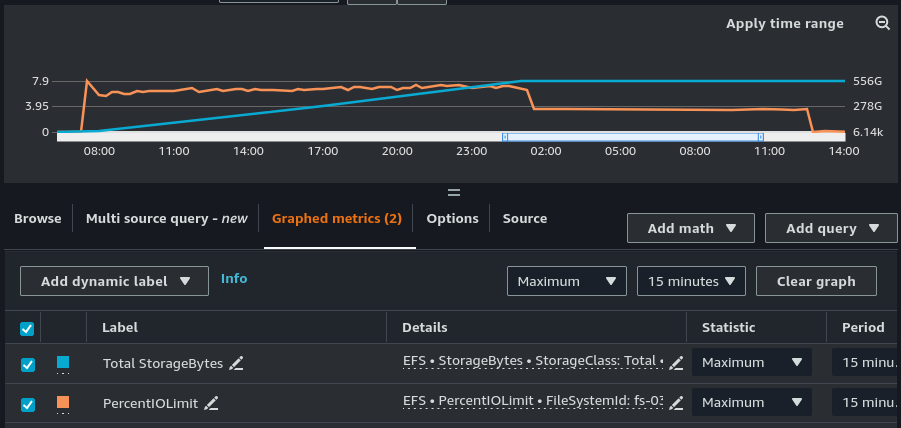
I checked the metrics of the EC2 instance and the EFS to see if there was some IO bottleneck but could not find anything that would indicate that. I guess there is a possibility that the StorageBox had a problem right at that time, I do not have any way to check that, but it seems unlikely to me.
Is it typical for restic to take this long to restore the metadata or could there be another bottleneck somewhere I am missing?
Any advice on how to speed this up would be greatly appreciated.
The metadata restores are a purely local operation, there are no further downloads from the storage backend at that point.
That likely means that it took one minute to restore the metadata for each folder. That operation is mainly limited by the latency of the filesystem on which the backup is restored, in your case EFS (based on your numbers about 20ms per file, restore performs at least 3 metadata operations for each file, which from my understanding of NFS might result in 3 open/close operations - those are rather slow unfortunately). When restoring to a local filesystem, that metadata operations are usually very fast. The metadata restore is currently no parallelized, so there are no tunables available in restic at the moment.
What likely helps is to restore the snapshot in multiple parts in parallel.
When I get the chance to do another restore test I will try restoring to a local disk and also parallel restore to the network drive.
I will post the results when I did that.
Within AWS a T3 instance has access to fractional CPU, based on a CPU credit system. If you check Cloudwatch you can look at your CPU credits, even if the instance has been deleted. Have a read here.
The other thing it could be is EBS volume credits, again it’s a credit system. Have a look here - this site is mainly for AWS exam revision but it’s quite informative.
Doing a local restore would help work out if it’s a Restic issue or an AWS issue.
I finally got around to trying this again.
By now the backup has grown to about 560GiB and 15 Million files.
With a t3.2xlarge EC2 instance the restore to a local EBS finished within just about 80 minutes, which is just about 1Gb/s. So that works just fine with restic.
I then used rsync to copy the files to an EFS. I did not have the time to do a full copy but I copied 1/16th of the files. That operation took 30 minutes, including copying the file metadata.
Projecting to the full restore it would take about 8 hours, way faster than restic would have taken in my initial attempt.
Maybe AWS EFS just does not work well with the way restic restores file metadata.