I use restic to upload backups to a S3 Bucket on web. Unfortunately, the buckets are getting bigger and the costs are getting high. So I decide to make a lifecycle on my backup buckets.
In order to perform the lifecycle, I ran a script on the server which connects to the bucket and than run a forget anf after a prune
some server are too important to the environment, so i can not afford to lose them during the prune action. So I decide to configure a directory with a fixed space and move the cache to it.
What do you mean by “lose them during the prune action”? What is the problem you are trying to solve? It’s quite unclear what you are concerned about with prune.
Sorry for not making the situation clear, but just before defining the directory for cache and fixing its size, when the prune command was run the cache simply filled the entire operating system disk, causing problems and almost crashing the machine.
That’s what I meant.
Prune is being run on the same machine where the backups originated.
Simply put:
Is there any way to define that the restic cache does not exceed a certain size
Not sure what the cache problem could be, but you can always run prune in small steps with the —max-repack-size flag, and that could help in your case.
The main problem with the cache during prune is that it takes up the entire system disk, and when I restrict the size of the directory where prune stores the cache, the action fails due to lack of space.
First, there is no possibility to limit cache size except using --no-cache.
Trying to use various options for prune will not help at all as in every case prune needs to read all metadata files - which will be immediately added to the cache - before even calculating what to do.
In case you start prune without an existing cache and if you are willing to remove any cache after the prune run, I do think that --no-cache would not loose much (if any) performance. I’m no longer very familiar with the current restic prune implementation but IMO there is no need to read any metadata twice, so there is no effect in having a cache - except of reusing data of prio / later runs…
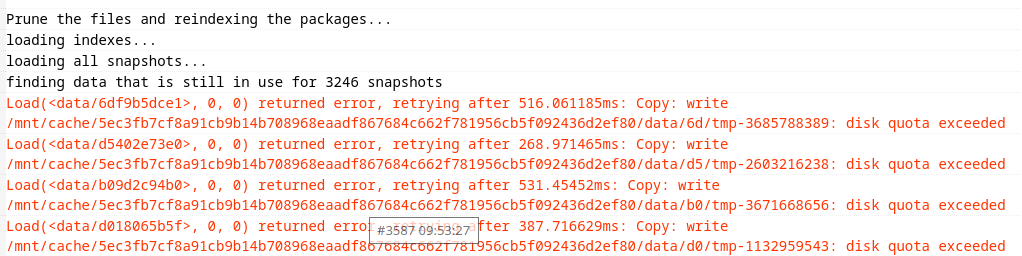
@srrs777 Can you please post some outputs of the prune run you are referring to. Without concrete examples we have to guess what you are worrying about…
restic will have to request every tree blob individually (only once, but the retrieval costs still add up), which will be rather slow when it has to be retrieved from anything that is not a local storage, unless the cache is enabled.
Ah, you are right. Enabling the cache allows restic to pre-fetch all packs files completely on their first access (if not existing in the cache) instead of accessing every blob individually from the backend.
My situation is as follows. I’m prune weekly so as to maintain a decent size of backups. Prune erases everything that is older than 180 days. Unfortunately the backup base is a ZFS dataset of 3Tb disk. So every time I run prune, the cache uses all the space of rootfs which causes a stop in the OS. When I change the cache configuration to a location with 100Gb the Job prune to due to lack of disk space. If I run with the --no-cache tag, the prune action takes at least two days. which is unthinkable. So I’ve been thinking that since in the past restic had a cache limitation flag, it could have today too. But this is not true. Therefore, I can’t find any suitable solution for cleaning very old backups via restic on very robust servers.
Never use rootfs for caching… as you are using ZFS create dedicated dataset with space quota and maybe reservation and point restic cache into it. Another benefit to isolate cache is that many systems run periodic snapshots on system dataset - in such case it is very easy to run our of space when using it for caching.
You can also run crontab job frequently deleting oldest files to maintain cache size. It should be much faster all together than --no-cache
You can adapt below script (I am not the author and grabbed it from Google long time ago and used often for similar cases) to your OS and requirement:
#Directory to limit
Watched_Directory=$1
echo "Directory to limit="$Watched_Directory
#Percentage of partition this directory is allowed to use
Max_Directory_Percentage=$2
echo "Percentage of partition this directory is allowed to use="$Max_Directory_Percentage
#Current size of this directory
Directory_Size=$( du -sk "$Watched_Directory" | cut -f1 )
echo "Current size of this directory="$Directory_Size
#Total space of the partition = Used+Available
Disk_Size=$(( $(df $Watched_Directory | tail -n 1 | awk '{print $3}')+$(df $Watched_Directory | tail -n 1 | awk '{print $4}') ))
echo "Total space of the partition="$Disk_Size
#Curent percentage used by the directory
Directory_Percentage=$(echo "scale=2;100*$Directory_Size/$Disk_Size+0.5" | bc | awk '{printf("%d\n",$1 + 0.5)}')
echo "Curent percentage used by the directory="$Directory_Percentage
#number of files to be deleted every time the script loops (can be set to "1" if you want to be very accurate but the script is slower)
Number_Files_Deleted_Each_Loop=$3
echo "number of files to be deleted every time the script loops="$Number_Files_Deleted_Each_Loop
#While the current percentage is higher than allowed percentage, we delete the oldest files
while [ $Directory_Percentage -gt $Max_Directory_Percentage ] ; do
#we delete the files
find $Watched_Directory -type f -printf "%T@ %p\n" | sort -nr | tail -$Number_Files_Deleted_Each_Loop | cut -d' ' -f 2- | xargs rm
#we delete the empty directories
find $Watched_Directory -type d -empty -delete
#we re-calculate $Directory_Percentage
Directory_Size=$( du -sk "$Watched_Directory" | cut -f1 )
Directory_Percentage=$(echo "scale=2;100*$Directory_Size/$Disk_Size+0.5" | bc | awk '{printf("%d\n",$1 + 0.5)}')
done
Until restic supports some sort of max-cache-size parameter I think this can be ok workaround