I have a repository to which I back up from devices A and B. Each device has duplicate data of its own, but there is also duplicate data between them (i.e. files that exist in both A and B).
I can check for the overall duplication status. Is there a way to check the volume of deduplication between source A and B only?
The rationale for that check would be to check the extent to which it is useful to merge sources A and B into one backup.
what you have not mentioned at all: have the repositories in question been created with the same chunker_polynomialvalue? If not, you cannot really compare the contents of repository “A” and “B”.
See ``restic cat config`` and ``restic init`` for more detail.
Only when chunker_polynomialare identical, a comparison will make sense. It is relatively easy to write a extension to an existing command to list all data blobs in a repository. One then could compare the data blobs across multiple repositories.
There is only one repository in OP post… question is about two sources deduplication stats:
Definitely @shd2h idea would produce results but at the cost of creating three repos. I think it could be simplified a bit with only one repo (but not post factum). Backup A first, record repo size then B to the same repo, both without compression. As A and B sizes are known, dedup can be calculated.
Data in question is definitely in one big repo - but I am curious myself how to get it.
This does mean using only a single repository, but it has an issue in that the OP explicitly mentioned they want to eliminate deduplication within the same client from the comparison.
If you use a single repository, and back both clients up to it, you cannot know how much of client B (the second client to backup) de-duped against the data from client A, and how much of client B de-duped against itself.
I could well be wrong, but my understanding is this should only matter if you’re actually comparing blob-by-blob.
If you’re only comparing the whole repository sizes on disk, the chunker_polynomial won’t matter. After all the same data is stored in both repositories, it is just split apart slightly differently.
That aside, if the chunker_polynomial was identical, comparing blob-by-blob would actually be possible wouldn’t it? In which case I think what you’re suggesting is something like this:
We create two repositories with identical chunker params (call them repo 1 and repo 2).
We backup client A to repo 1, and client B to repo 2.
We list the blobs from both repositories. As the chunker params are identical, the data will split the same way across both repositories.
Any common blobs to both repositories can be assumed to combine/dedupe perfectly if the repositories were combined.
By summing the space used by the common blobs, we can then know how much space could be saved by combining the repositories.
Have I understood that correctly? If so it would let us avoid creating a third repository for comparison, at the cost of some additional technical complexity
Whole discussion is getting over engineered a bit:)
The original question boils down to very simple one. In the simplest form it is repo with two snapshots. One from host A and one from host B. What is data overlap between these two snapshots aka how much space I save thx to dedup.
This information is in such repo. How to calculate it? It is interesting challenge:)
Sorry, my eyes did not read properly. In this case (=one repo) this will be a data blob by data blob comparison, which can easily be achieved. This could either be done by a snapshot to snapshot (see command ‘restic diff’) comparison or more broadly by a host to host comparison of various snapshots involved.
Doesn’t this command operate on files level only? When deduplication can occur also of files’ fragments - not such uncommon thing when for example there are VM images, edited video files etc.
I would write an extension to the diff command which would do a comparison based on data blobs. By using the standard snapshot filter and two new options ‘–host1’ and ‘–host2’ the extension would compare data blobs on both sets of snapshot(s).
Will it work on restic repo? I know that rustic is fully compatible with restic repository format but it also stores some metadata not available in restic
@kapitainsky All rustic commands are designed to also work on repositories created by restic. read-only commands will even keep the repository unmodified.
You are right, there are some extensions in the repo format to support feature which restic does not provide. In most cases, however, rustic commands work on the “original” repo information. And here the information can be computed using information about needed data blobs and blob sizes, as @wplapper correctly pointed out.
Of course you need to configure rustic to be able to access the repository (there are users who are having trouble with specific remote backends which may be either due to the different configuration or due to differences in how the access is implemented).
TL;DR: if you can access your “restic repo” with rustic, this will work!
Thank you. Great to know. @Wpq has now the way to answer his question:)
I use both restic and rustic without any issues. Noticed though that in case of rustic repo running e.g. restic rewrite strips some “eye candy“ useful stats I have compared to when using rustic only. And only wondered if in this case it is not needed. Of course it does not impact core interoperability and such repo is still usable in both programs.
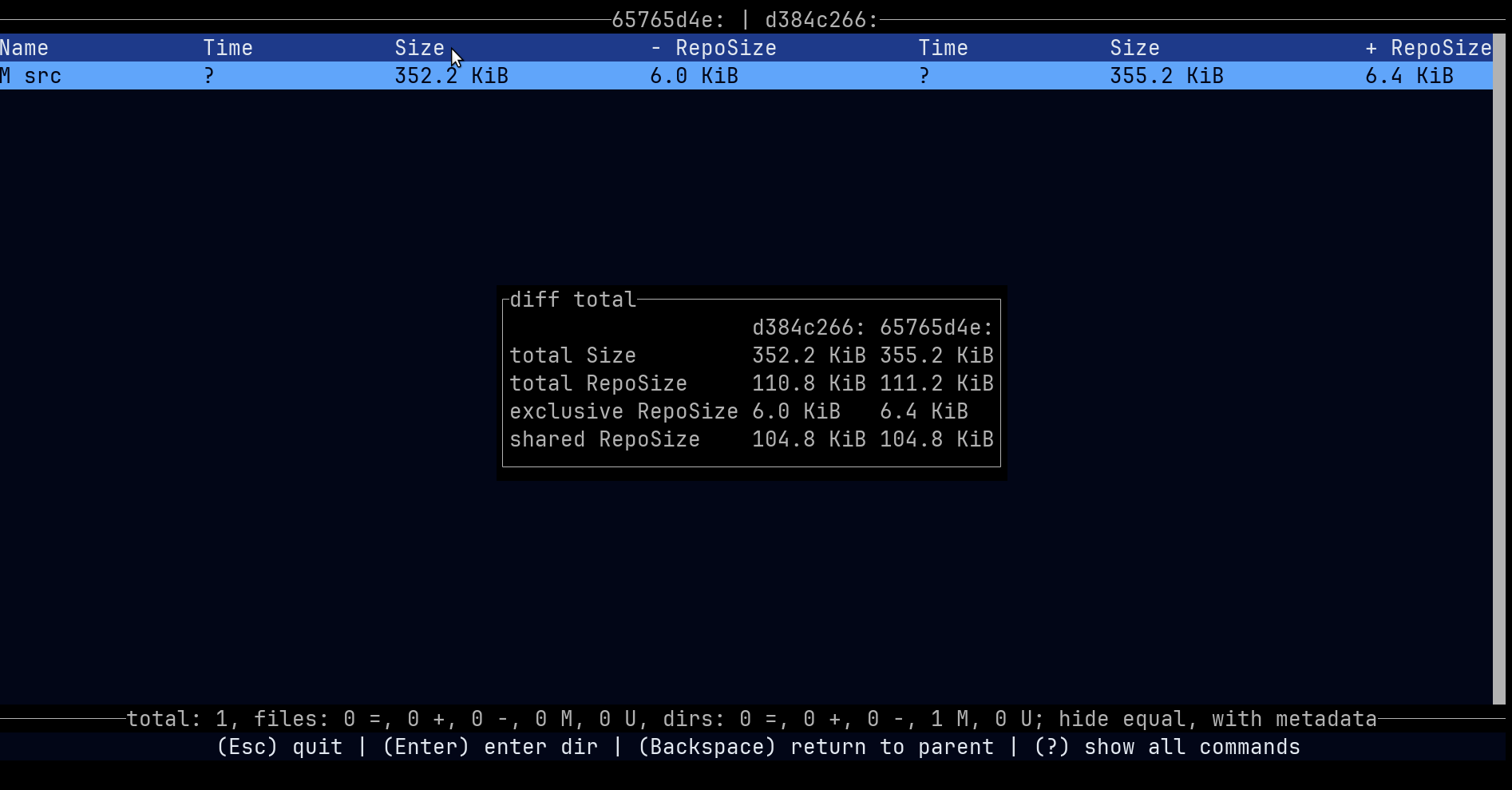
The diff command in restic already calculates the list of common blobs. So I guess the only thing missing here is to print their size? (And maybe also report identical files, although that will be less useful across hosts)
Hello all, #
now that the PR #5613 has been merged, I have worked on diffing two host in one repository and find differences and commonalities for these two hosts. I haven’t formalized a new PR for this, but this is current output:
./restic -r /srv/restic-repo diff --diff-hosts Mint21-nvme XPS-15-9550 --path /home -q
host A: Mint21-nvme host B: XPS-15-9550
10447 common data blobs with 859.254 MiB
11125 only host A blobs with 5.292 GiB in 51 snapshots
41233 only host B blobs with 6.041 GiB in 20 snapshots
62805 counted blobs with 12.172 GiB in 71 snapshots
and the same in --json mode:
{
“message_type”: “host_differences”,
“host_A”: “Mint21-nvme”,
“host_B”: “XPS-15-9550”,
“host_A_snapcount”: 51,
“host_B_snapcount”: 20,
“common_blob_count”: 10447,
“common_blob_size”: 900992751,
“host_A_only_blob_count”: 11125,
“host_A_only_blob_size”: 5682099840,
“host_B_only_blob_count”: 41233,
“host_B_only_blob_size”: 6486696276
}
Would that be an acceptable output? All comments /recommendations are welcome.
For diff it would be typically left and right. However, for me using only allowing to select hosts for left and right feels too much restricting. The same analysis may be interesting for other filter criteria or even arbitrary sets of snapshots….