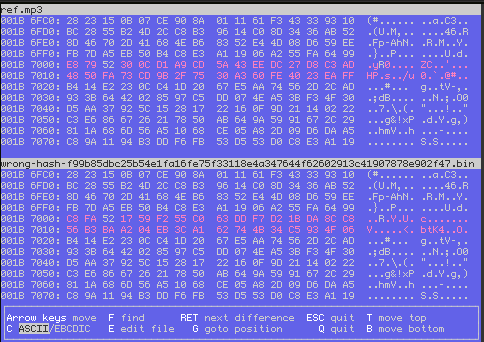
I made a ~1T snapshot, but trying to copy the repository from another machine caused this after several hours (after importing about 260G of data):
LoadBlob(9f02880a10db561af97a6e1d69d3cc85936951fc6eb020c638f5422ea2268c27) returned error blob 9f02880a10db561af97a6e1d69d3cc85936951fc6eb020c638f5422ea2268c27 returned invalid hash
Context
the host machine is an anemic mips machine, not very reliable
the snapshot took about a week to make
the backup machine is remote and much more reliable
the backup machine uses rest-server (append only)
Investigation
% restic -v stats
repository 390a6747 opened successfully, password is correct
scanning...
Stats in restore-size mode:
Snapshots processed: 1
Total File Count: 157211
Total Size: 991.686 GiB
% restic -v check
using temporary cache in /tmp/restic-check-cache-341950296
repository 390a6747 opened successfully, password is correct
created new cache in /tmp/restic-check-cache-341950296
create exclusive lock for repository
load indexes
check all packs
check snapshots, trees and blobs
[0:07] 100.00% 1 / 1 snapshots
no errors were found
% restic -v find --blob 9f02880a10db561af97a6e1d69d3cc85936951fc6eb020c638f5422ea2268c27
Found blob 9f02880a10db561af97a6e1d69d3cc85936951fc6eb020c638f5422ea2268c27
... in file /cen/so/red.mp3
(tree f73fb24fa4f8c0885452a51c3d97912efe44fd8f72907eda446bcada4463a309)
... in snapshot cd60b511 (2021-08-29 00:57:08)
I did check the integrity of the file on the host machine (compared to another reference of that specific file I had backed up somewhere else) and it’s correct.
Trying to figure out what the data looks like on the repository to compare how it is altered, but:
The copy command cannot skip invalid blobs, as that would essentially cause the new repository to be broken. What you can do is run restic check --read-data to let restic verify every singe blob.
As the error is “invalid hash” and not a decryption error, this means that it most likely was a bitflip on the host creating the backup.
That corruption pattern sounds like the bitflip occurred during encryption, but before calculating the authentication code for the encrypted ciphertext.
The simplest way to fix the repository would be to fix the content of the file with the wrong hash. Then remove the damaged pack-file, run rebuild-index and then backup the extracted pack contents. Afterwards the repository should be fine.
That’s a superb writeup, very very cool! Thanks so much for sharing your story and in particular the details of how you figured it all out and manually patched your repository!
Careful, this is not a tutorial, your mileage may vary. Typically, what the story doesn’t tell is that I got a 2nd similar bitflip in that same backup/snapshot later on. In that 2nd scenario, it was the last out of 4 blobs again, but it wasn’t starting at the beginning of the file, so I had to truncate the reference file with a skip option after identifying the correct offset (which I did simply by searching a binary string).
After changing the content of the pack file, you also have to update the pack filename (and run rebuild-index). The pack file name is expected to match the sha256 hash of the pack file content. Right now restic check --read-data-subset 254/256 should report an error.
The nice part about using the high-level repair workflow is that there are next to no special code paths involved. Actually the only special code is that which check whether a file should be read again due to missing blobs. However, when just running backup on the folder which contains the extracted blobs, that is also not relevant either. And the code to rebuild the repository index is also nearly identical to what is used for the prune command.
As you know the full blob id, I’d recommend to call find with the full id
Yeah I actually did but it was easier to understand with the short version (more presentable for a blog post).
After changing the content of the pack file, you also have to update the pack filename (and run rebuild-index). The pack file name is expected to match the sha256 hash of the pack file content. Right now restic check --read-data-subset 254/256 should report an error.
Ah that’s correct. I just tried that: copied the pack file to its correct hash in the appropriate directory, and ran rebuild-index, but the check still fails: Pack ID does not match, want fdd48b5c, got 81b4816c. (81b4816c is the new name, both packs are present).
The nice part about using the high-level repair workflow is that there are next to no special code paths involved. Actually the only special code is that which check whether a file should be read again due to missing blobs. However, when just running backup on the folder which contains the extracted blobs, that is also not relevant either. And the code to rebuild the repository index is also nearly identical to what is used for the prune command.
Yeah as explained it was also a learning experiment, because I do not understand what the top level tools do. Typically, I should have made the indexing myself, because now I have no idea what changes were made and I have little clue how to move on…
Do I understand you correctly that the pack file is now contained twice in the repository? Once with the old, wrong name and once with the new, correct one? If yes, the just remove the file with the old name, then run rebuild-index and then your repository should be fine.
Do I understand you correctly that the pack file is now contained twice in the repository? Once with the old, wrong name and once with the new, correct one? If yes, the just remove the file with the old name, then run rebuild-index and then your repository should be fine.
Yeah they are present twice, but since last time there is a new plot twist: the invalid blob are also present in the tree now (I did make a new backup snapshot, which includes a directory with the invalid + valid blobs manually crafted, because I wanted to keep a trace of them).
rebuild-index was not enough to fix the problem. As far as I can tell there is a double reference somehow.
I guess I’m going to have to inspect the index file(s?) and try to fix that manually.
What errors does check report at the moment? I don’t see why it should be a problem to have a snapshot that includes the invalid+valid blobs. From restics perspective blobs are either stored in a pack file or not. And in the latter case, the backup will add invalid blobs as new blobs with their correct sha256 hash as blob id to the repository.
Assuming the pack file with the wrong filename is no longer in the repository, then all references to that pack file should have been removed by rebuild-index (which using restic >= 0.12.0 will report which changes were made). If that were not the case, then check will report that a pack file is missing.
I’d strongly recommend not to manually modify the index files. This will most likely either damage the repository, let check report errors and prevent prune from working. If a plain rebuild-index does not work, you could try rebuild-index --read-all-packs which recreates the index from scratch. If that doesn’t help then the problem is very likely that some pack file is still messed up.
The index essentially contains only the information that’s also stored in the pack file headers. That is which blob exists at a certain position in a pack file.
Oh my bad: I was keeping the original pack files because I though they were needed because I was keeping a copy of the broken dumps into the backup itself.
Removing them and re-indexing did indeed fixed the problem, thanks!
I will run a complete read check just to make sure, and make an edit on the blog to mention the rename of the pack file + re-indexing.
The important thing to understand is that restic doesn’t care in which pack a blob is stored, as long as the blob exists somewhere in the repository. And that is also the reason why the repository index is required in the first place. Otherwise restic wouldn’t know where to look for a blob.