Hi all, Im running a bash script that backs up our client data using restic, onto a NAS mount
running the script on a physical centos 7 (16 cores, 800gb RAM), with bandwidth between the server and NAS at 20mbps, using restic v 0.9.5
heres the bash script that runs it, my cache dir (/mnt/hc2/cache) are local SSD disks that are on a mdadm raid=5 config
cache_dir="/mnt/hc2/cache" # restic cache
repo_dir="/mnt/nas1/servers/restic" # Synology NAS1
# directories on /mnt/hc and /mnt/hc2 that need to be backed up
backup_dirs=(
"/mnt/hc/hdbs/clients"
"/mnt/hc/billing/ice_mappings"
"/mnt/hc/hdbs/prod/refdata"
"/mnt/hc/hdbs/prod/txns"
"/mnt/hc/hdbs/prod/derived"
"/mnt/hc2/hdbs/prod/derived"
"/mnt/hc/hdbs/prod/sym_files"
"/mnt/hc/hdbs/prod/sync_hdb_tmp"
"/mnt/hc/hdbs/prod/clients"
"/mnt/hc/hdbs/prod/dc"
"/mnt/hc/hdbs/prod/sync_rtos"
"/mnt/hc/hdbs/prod/sync_rtos2"
"/mnt/hc/hdbs/prod/tw_csvs"
"/mnt/hc/hdbs/prod/mktdata/mkt1"
"/mnt/hc2/hdbs/prod/mktdata/mkt2"
"/mnt/hc/hdbs/prod/mktdata/mkt3"
"/mnt/hc2/hdbs/prod/mktdata/mkt4"
)
# mount NAS
mountpoint /mnt/nas1
if [ $? -eq 1 ]
then
mount -t nfs nas1:/volume1/backup /mnt/nas1
[ $? -eq 1 ] && {
echo "unable to mount NAS1"; exit 1;
}
fi
for current_dir in "${backup_dirs[@]}"
do
[ -d "${repo_dir}/${current_dir}" ] || restic init -r "${repo_dir}/${current_dir}"
restic unlock -r "${repo_dir}/${current_dir}" 2>> $log_file
}
restic backup -v --cache-dir=$cache_dir -r "${repo_dir}/${current_dir}" "${current_dir}"
## check consistency
restic check -v --cache-dir=$cache_dir -r "${repo_dir}/${current_dir}" 2>> $log_file
## prune
restic forget --keep-last 2 --prune --cache-dir=$cache_dir -r "${repo_dir}/${current_dir}"
echo -e "[$(date +%Y%m%d_%H%M%S)] backup of ${repo_dir}/${current_dir} complete\n\n\n" 2>> $log_file
done
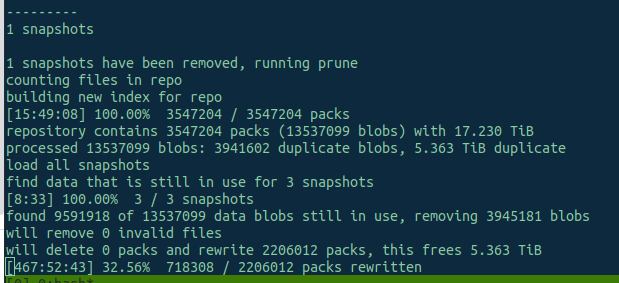
its taking over 460 hours to prune 5.3 TB of data, is this normal? Is there anything I can do to increase backup and pruning speed?
First of all, I’d suggest a newer version. There were some changes since 0.9.5 which affects both speed and safety.
1 Like
Pruning speed was improved by orders of magnitude in restic 0.12.0.
See also the documentation on how to customize pruning in newer versions of restic.
1 Like
Pruning is an intensive process - I’d advise against performing it on every backup run. Also it’s my understanding that habitual unlocking is advised against, and I’d also avoid performing any writes (forget or prune) before knowing that the check passed without errors. I tend to be paranoid and only run it after the entire repo has passed a check --read-data.
thank you for tips, ill try upgrading version, running without pruning for a while
1 Like
If it helps, you can avoid repacking with restic prune —max-repack-size 0. This way, prune only deletes unused data files and uses much less resources.
1 Like
Pruning is an intensive process
Recent prune versions are actually not that much intense. There are basically two time-intensive parts:
- Searching for used blobs by traversing all trees of all snapshots. This is also the time-consuming part of the
check command (when called without --read-data)
- Repacking packs. This however can be heavily controlled by the
--max-unused and --max-repack flags and even with the defaults repacking is diminished a lot.
@ProactiveServices: IMHO you are too paranoid when running pruning only after check --read-data.
There is only one kind of problem the --read-data would prevent: You have duplicates of blobs where one duplicate is ok and another one is corrupt AND prune would remove the ok one. However duplicates should not be the normal case and usually result from aborted runs (actually often aborted prune runs)
If you have an unused corrupt non-duplicate blob, prune would simply remove (or keep) this without changing anything and if you have an used corrupt blob, prune would always keep it (either not touch it or abort when trying to repack it) - again without changing the situation.
So, if you fear corruption of pack files you better invest in mechanisms to avoid that in your storage!
Besides this:
prune does run all checks check would perform which would lead to prune damaging the repo.- Moreover, if prune at any stage runs into a situation which may induce data corruption, it simply aborts. This is usually during the phase where it determines what it should do.
- The main principle for removing stuff in
prune is: Before removing anything which is or may be referenced, first write the new thing which replaces this dependency and then remove the now unreferenced old data. This principle ensures that if prune aborts at any time, it will leave an uncorrupted repo. (This principle is also the main reason why aborted repack operations lead to duplicates)
1 Like
Just going by what’s mentioned in the docs and I am not convinced that fully checking a repository’s integrity before performing writer operations is too paranoid 
Well, of course you are free to do what you like to do. IMO running check --read-data before prune in order to “secure” the prune run is too paranoid. The better catch would be anyhow to run it after prune as also mentioned in the docu - if you are paranoid about the pruning algorithm.
That said, a check --read-data run turned out to be an excellent method to checking integrity (or failures) of your storage in case you (or your storage provider) have not set up other regular methods. So it might be still advisable to run it regularly.
2 Likes