Okay, I just wanted to make sure I was doing this right.
I have a cloud repo that multiple clients back up to. I periodically sync it to a local hard drive (mostly for quicker recovery times / prune operations) using “rclone sync --delete-after”.
Now, sometimes I want to back up a bunch of data quickly. In the past I’ve thrown a “fake” lock file (from a prune operation) into the “lock” folder, sync’d the latest version down, sync’d one more time to make sure there was no more data (aka active backups), then backed up to the local repo, then synced back to the cloud when I had time. I’m talking ~600GB backups, for instance.
Would a better idea be to just back up to the local repo (after a quick rclone sync from the cloud), then use “restic copy snapshot-ID” to copy from the local to the cloud, then one more rclone sync from the cloud to the local? Are those syncs even necessary, or can I just quickly backup data to (the unsynced) local repo, “restic copy” the snapshot to the cloud, then (optionally) bring them into sync at my leisure? I’m assuming I might get duplicate data should I not bring them into sync first, but that’s a minor issue.
Just wondering what the best practice would be to back up a LOT of data locally to a cloned repo, then bring them back into sync. Thanks!
1 Like
restic copy is intended to copy data between independent repositories. So these will end up with totally different files in the repository (although the snapshot content is the same). That effectively prevents you from using rclone sync for these repositories, by making it totally inefficient.
If you start with a single repository, then make a full copy somewhere else (I mean a file-level copy here, not the copy command). Afterwards you can create a new snapshot in both repository copies and then merge them by copying new files to the other repository. This way of merging repositories works as long as you don’t run prune on either copy. From that point on the repositories will diverge. You can of course merge the repository copies first, then run prune on one copy and sync all changes to the second one.
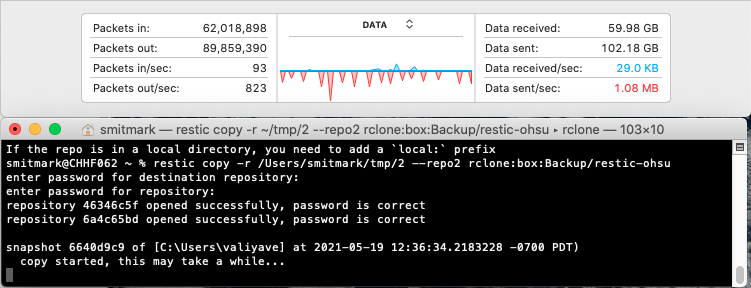
So just to test this, I made a new repository on an SSD to quickly backup a machine. It was about 150GB and deduped to about 60GB. I tried to copy the snapshot from the new repo to my big repo on Box… and it’s been going for over two days now and doesn’t appear to be doing much? I upload to Box around 30-60MiB/s depending on the day, so I’d honestly expect it to be done by now - or at least to see a little more upload bandwidth being used…?
The download and upload part of the copy command is unfortunately not yet optimized for performance. Currently it processes one blob after the other.
1 Like