Hi all,
I had over the weekend an interesting file system encounter that coupled somewhat to my restic backup. Testic worked as intended and never was at fault, I learnd a bit about my backup approach/set up, so I would like to retell it.
I have been running backups from my laptop to a remote bucket with restic for some time. For that, I had wrapped restic in a small bash script, that gets started regularly by systemd service/timer units.
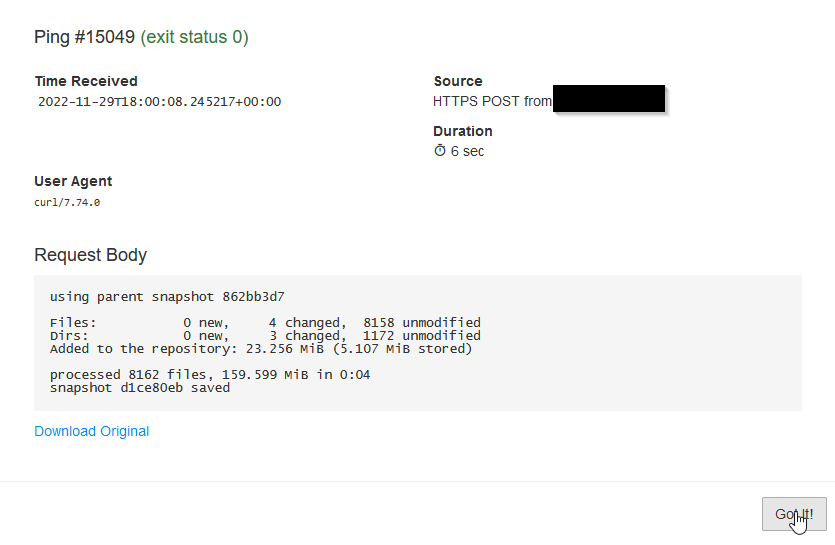
However, I only noticed yesterday, that no backup run had succeeded since a few month - i.e., unnoticed, the unit started but never had finished successfully.
restic backup had always been throwing an error message
Fatal: unable to save snapshot: node "prefs.js" already present
and exited. But since my wrapping bash script has not been in a “safe mode”, the exit code was followed by a few more lines (mostly echos) finishing successful so that the whole unit returned 0 to systemd and everybody was (superficially) happy.
It turned out to be a file system corruption. My volume is on btrfs (seeing why RHEL has dropped btrfs for good some time ago…). While another unit regularly scrubs and rebalances the volume, it did not catch the error: a file prefs.js had multiple entries in its parent directory, i.e., it appeared three times in the diorectory while seeming to be the same(??) file (only one inode for what it’s worth in btrfs).
While I could read the file and cat it into a new one, I could only delete one entry and was mot able to delete the dangling other two entries (no obvious white spaces in the names or so). I “fixed” it in the end by tar’ing the whole directory tree, removing the whole dir/tree and unpacked the tar again.
Now my scripts are using the “unofficial bash strict mode”, that should exit for good and throw a proper error towards systemd, when a problem occurs.
http://redsymbol.net/articles/unofficial-bash-strict-mode/
My main lessions are, that even with scrubs (apparently only on blocks but not checking trees) a brtfs can be in an unhealthy state and that a wrapping backup script should fail for good ![]()
Cheers,
Thomas