Thanks for replying!
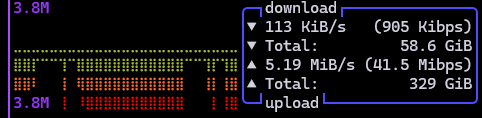
The image timescale is 1 horizontal dot = 2 seconds. The ping is ~100 ms during the gaps and ~105 ms when the upload bit is occurring.
I used my router’s traffic monitor to get specific times, and the send is for 42 seconds and the gap is 22 seconds, which takes my 40 Mibps upload down to 26.25 Mibps effective (best case ignoring ramping).
~100 ms is on the order of spinning hard drive latencies so I found fio in this forum post ssd - How to check hard disk performance - Ask Ubuntu and applied it to see the latency for 16MiB chunks in sequential read/write (to match restic’s 16 MiB ~chunks~pack size).
(To use cd to the drive’s directory you want to test; you have to delete fio-tempfile.dat yourself afterwards)
Read:
sudo fio --name TEST --eta-newline=5s --filename=fio-tempfile.dat --rw=read --size=500m --io_size=10g --blocksize=16m --ioengine=libaio --fsync=10000 --iodepth=32 --direct=1 --numjobs=1 --runtime=60 --group_reporting
Write:
sudo fio --name TEST --eta-newline=5s --filename=fio-tempfile.dat --rw=write --size=500m --io_size=10g --blocksize=16m --ioengine=libaio --fsync=10000 --iodepth=32 --direct=1 --numjobs=1 --runtime=60 --group_reporting
slat = submission latency, clat = completion latency
Local spinning drive (read avg / read stdev | write avg / write stdev - all in ms):
slat: 82.183 / 29.899 | 4.442 / 29.969
clat: 1489.66 / 781.72 | 2698.53 / 220.98
bw: 180 MiB/s | 176 MiB/s
Remote samba share mounted as a drive mounted (read avg / read stdev | write avg / write stdev - all in ms):
slat: 4.054 / 1.381 | 5.184 / 1.708
clat: 445,418.11 / 33.92 | 33,863.15 / 18,399.84
bw: 8.906 Mibps | 23.984 Mibps
So clearly there’s a massive lag for the remote when doing file operations. I believe fio breaks on the remote read call because the entire fio read command lasted the same 446s, and I can ls in the directory with what feels like 1 second of lag to see contents.
As noted above, rclone seems to be able to sidestep the issues restic and fio run into and operate at the full possible bandwidth while using its local driver (alias remote='/mnt/remote').
Switching from -r /mnt/remote/restic-backup to -r rclone:backup:restic-backup made it worse;
16s of send and 26s of gap yielding 15.24 Mibps avg.
Using the rclone direct samba remote rclone:backup-samba:backup_usr/restic-backup removes the gap but it cannot hit the maximum 40 Mbps ever and instead oscillates between 25 Mibps and 30 Mibps, which is still an improvement over the gap speed.
It takes a long, long time to do the initialization because this repo isn’t finished uploading yet, but I will try 20 concurrent connections instead of 10 in several hours. Edit: no improvement with more connections
Is the difference between rclone and restic’s handling of the local backend with a samba remote mount (which rclone has no trouble saturating 40 Mibps) that rclone confirms the uploaded data is safely written to the disk asyncronously and continues uploading new data while restic does not? Guessing at what yields the observed gap.