I’m testing using --stdin backups to B2 storage for the typical case of backing up databases using SQL dumps using restic 0.9.1.
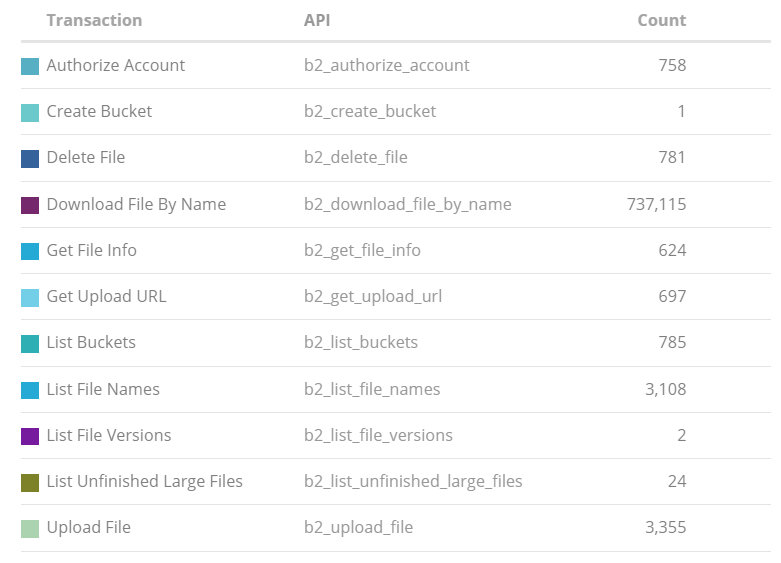
They are small databases with about 16 backups per hour. For the first about 48 hours here are the B2 API stats (for about 600 backups). Clearly the b2_download_file_by_name heavily dominates, and there are a lot of them.
I realised that I am failing to provide persistent storage for restic’s local cache. So restic is probably re-creating the local cache each time, which might be a lot of those b2_download_file_by_name occurrences. I have fixed that now, so we’ll see if that reduces the number of b2_download_file_by_name uses per backup.
Right now I am gzipping the SQL before passing it to restic. Also the --stdin-filename is currently date stamped - so unique for each run. I assume these two things mean that each snapshot is independent with no block deduplication.
Would I be better to using the same --stdin-filename filename for each database, so parent snapshots can be identified by path?
And would backing up uncompressed SQL be more likely to be more efficient for subsequent backups than compressed SQL? Lossless compression with the same algorithm and settings is generally predictable, so block de-dupping might work either way?
That’s likely the cause. In your particular use case, restic will re-download all index files every time it starts.
Not necessarily, but since you’re using gzip it’s very likely that not two backups share any blocks. If you remove the gzip before feeding the data to restic, it will be much more efficient, it is able to (and will, automatically) detect reused blocks even if the file name is completely different.
Would I be better to using the same --stdin-filename filename for each database, so parent snapshots can be identified by path?
For reading data from stdin, this is not necessary. Finding a parent snapshot is only relevant for backups of a file system, because then restic can decide to skip reading unmodified files. Data read from stdin must be read regardless of whether or not there’s a parent snapshot, since there is no timestamping information which indicates if data has been modified.
And would backing up uncompressed SQL be more likely to be more efficient for subsequent backups than compressed SQL?
Yes, I guess so. But it depends a lot on your data, if you have many small tables into which often records are inserted, then I’ve received reports that deduplication does not work so well on the data. restic uses rather large blocks (up to 4MiB).
I have kept the timestamps in the filenames and added tags. I kinda wish tags were name+value, but they are still great to have.
There is minor annoyance that an unwanted path gets prepended (#1809), but I know you have that in the backlog.
Thanks for the info about block size, I doubt I’ll benefit from de-duplication over compression in my case. But if I were to test that, how could I tell? Is there a stats command to tell me how much or many blocks of a snapshot are unique and not a reference to blocks in previous snapshots?
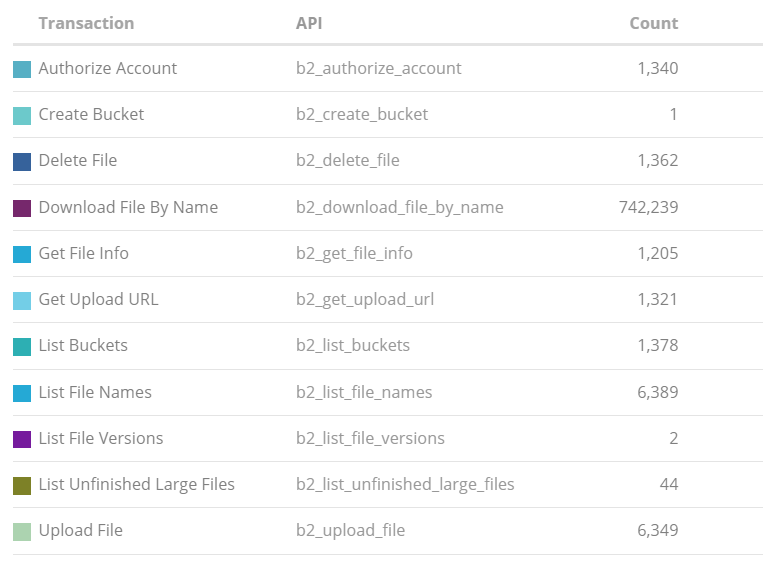
What a difference keeping the cache and not rebuilding it every time makes! In this case it reduced the b2_download_file_by_name calls down from ~1000/backup to ~10/backup. That saves ~345,600 API calls per day, saving $0.14 per day.
It would be handy if restic logged when it was creating/downloading a new cache. Even if only in verbose logging. That would have helped me spot my omission sooner (#1897)