I had to download everything from my gdrive to my NAS. I’ve used rclone as backend, and used rclone sync to download everything, despite have a few duplicated files, I don’t think anything was wrong.
The problem now is that I want to be sure my backups are good. I already ran check and had no errors, but I am now running check with --read-data and it’s quite slow.
It’s been 25m and only 0.5% packs checked.
I can check my freenass and it does not seem to be overloaded. ( i maybe wrong here)
But I just want to see if there is an option to make sure restic runs as fast as the disk can respond…
Which version are you using? If you are on an old restic version, it will be much slower than recent ones. Make sure to be on the latest one, version 0.15.0 which you can find at Release restic 0.15.0 · restic/restic · GitHub .
You should also explain how you are running restic, what command are you using?
Version is 0.15, but the backup one used was over many restics version… I actually still in v1 After the check, the next step will be trying to change the version.
The command: time ./restic_0.15.0_freebsd_amd64 check --no-cache --read-data -r /mn/repo/.....
I was now just thinking if i can run at the same time a few restics using the --read-data-subset options
But i can’t because of the lock… no sure if running with --no-lock is wise for this…
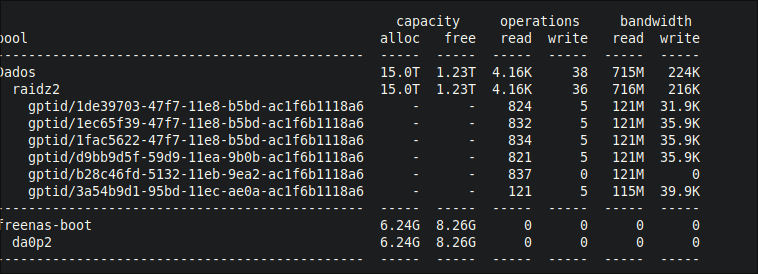
Everything is running in the same freenass, disks (actually pool) is local, so i am accessing local disks (raidz2)
I had to add the no cache option otherwise the freenass disk would get ful (very low on root) , another option would be to add cache folder on the same pool that the data is storage, but I assumed that would not make sense, or i am wrong?
Just to be clear:
freenas machine
Single pool/vdev of raidz2 with 6 disks (94% ocupied, freenass is saying this slowdown performance)
freenass os is installed on USB flashdrive
I am running restic directly at the freenass of over ssh.
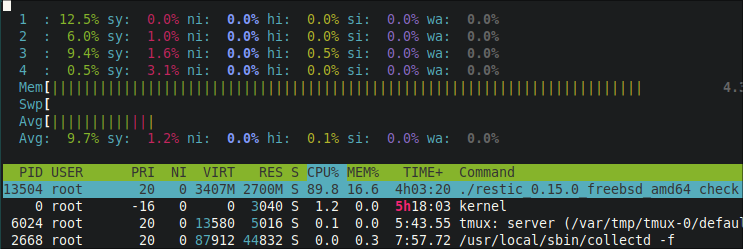
cpu avg is low, from 10 to 40%
single cpu load somet
16GB of ram, about half of it is zfs cache
8 cpu cores ( Intel(R) Xeon(R) CPU D-1518 @ 2.20GHz)
from htop, restic is using about 18% of RAM and from 40-60% cpu (but because we have 8 cores, this could go to 800%)
Let me know if I should add cache folder to be at the same pool of the actual data.
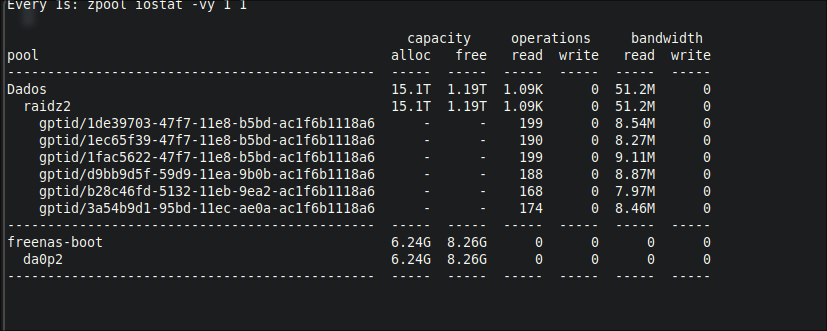
as of now, we have 2h and 50m and around 4.3% of pack read
Well, putting the cache on the same disk as you are checking the data on will not be great, it’s better to put it on a separate disk of course, to get as much IOPS for your data checking as possible.
I am now and then checking a couple of TB of data and it too takes a while on 7200 RPM disks. I have it on XFS though, not ZFS. I don’t really think it’s restic that is being slow, it’s more likely your disk system that can’t keep up well. Especially since your other resources don’t seem saturated at all.
I do agree it feels slow at that speed, but I think it would help to have a cache enabled if you can (on other disks than the one’s you are checking from/on).
Stupid me… The cache is by default not used by the check command. There is a --with-cache option one can apply in order to make it use the cache. But this means then that your check run right now is not using the cache. Still it’s probably a matter of slow disk I/O.
Weird, I don’t know how the disks can be that slow… but it could be the case… I will do other tests on disk speed read to see if I can get better performance…
I will also try to debug more the disks performance/speeds
As far as I know, and assuming a recent version of freenas, ZFS scrubs are primarily sequential I/O:
A scrub is split into two parts: metadata scanning and block scrubbing. The metadata scanning sorts blocks into large sequential ranges which can then be read much more efficiently from disk when issuing the scrub I/O.
I don’t believe a restic check is going to be as “nice” a workload for the pool as the scrub. I’d expect more random I/O basically, because restic isn’t aware of which blocks are contiguous on disk, so it has no way of trying to make all the read requests sequential like a scrub does.
Your 120MB/s figure looks fairly reasonable for a mostly sequential workload. The more random I/O is included in the the workload though, the lower the performance is going to be relative to this.
To offer a point of comparison, I triggered a restic check --read-data against a repository hosted on a btrfs raid1 filesystem, and got around 50MB/s average on one disk (older, 7200rpm drive), and 65MB/s on the other (newer, 5400rpm drive).
Ugh, nevermind, ignore my numbers, I think my setup is network bottlenecked.
(Longer explanation: In my setup, the system hosting the repository has a slower CPU, so running restic locally delivers significantly worse performance than running check remotely from the client. Client and server are connected via a 1Gbps link (125MB/s). 50+65~=115MB/s so add in a little bit of extra for network overhead and you get the 125MB/s figure).
--read-data processes each pack file sequentially. As the pack files are usually 16MB (since v0.14.0), they shouldn’t be too fragmented. At least that’s what I’d expect. How much CPU is restic using?
CPU usage was explained above, but right now its at arount 80-100% (one core only) the cpu has 8
I’ve also enabled cache to see if there is any differences,