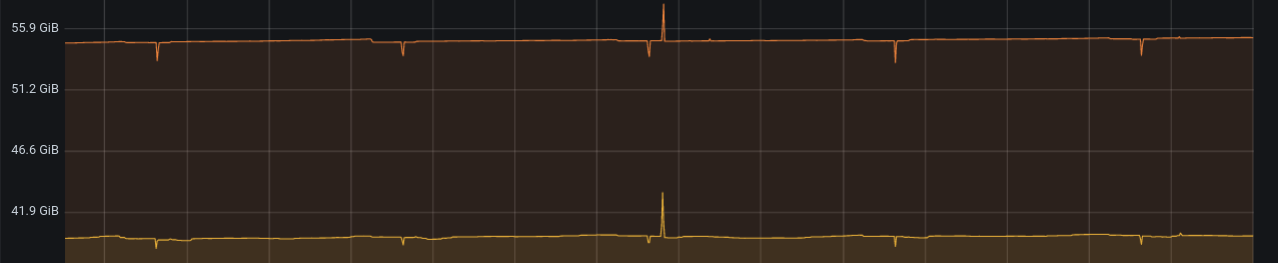
Small dips you see are the deletion of target folder before I re-dump the database backup (which is negated after new dump quickly). Then restic runs after short time. Used command is:
It’s normally not visible since I don’t expect too much of a disk usage from restic. But before the peaking one in the middle, there was prune running on the repo. Which is understandable due to changes prune will do on the repo.
So I have 2 questions:
Is there a way to prevent this peak? I feel like restic is doing its safe default of “first write, then delete” on local cache too, which might not be the optimal way imho, considering cache is not critical for data integrity. If we decided to fetch new data to fill the cache, would it make sense to “delete-(while|before)-writing” to prevent peaks? Not sure about technical possibility though, just theorizing.
Would it make sense to open a feature request for adding cache-related statistics to be added to the backup command’s json output ?
The cache just mirrors the operations done on the repository. It could be possible to remove some of the files from the cache earlier on, before they are actually deleted from the repository, but that makes the code more complex. And it might be necessary to cache the old and new data to allow resuming from an interrupted prune run, so the additional space should be available anyways.
What do you expect to learn from additional cache related statistics?
I thought seeing some kind of added/removed/total size information regarding caches might be useful.
But those files are already removed from the repository. Timeline is:
Backup: fills cache
Backup: uses cache
Prune is done (triggered from another host)
Backup: re-fills the cache first, then removed the pruned elements
I thought if our entrance point is “snapshots”, after getting the latest ones maybe we’d know which indexes (&data) to wipe before pulling new ones. But yes, even this assumption would add complexity
Hmm correct, I don’t trigger prune from these clients, so I overlooked this.
Problem is: A big enough repo is causing 4.5GB cache folder on these hosts, considering this “double usage” after prunes, it adds up. I’ll need to think something else. Afaik there is no practical way to limit cache folder, and I suspect restic won’t react good if I put the cache on a limited-size separate filesystem etc.
Maybe I need to manually wipe the cache folder after a prune flag is set somewhere.
That timeline only works with two different restic clients. And the only overlap is in regard to the repository index. It might be possible to cleanup the cached indexes before downloading the new ones.
Prune itself already cleans up its local cache. In addition restic automatically removes no longer required indexes and no longer reference pack files once it starts using a cache.
 ?
?