> restic version
restic 0.18.1 compiled with go1.25.1 on windows/amd64
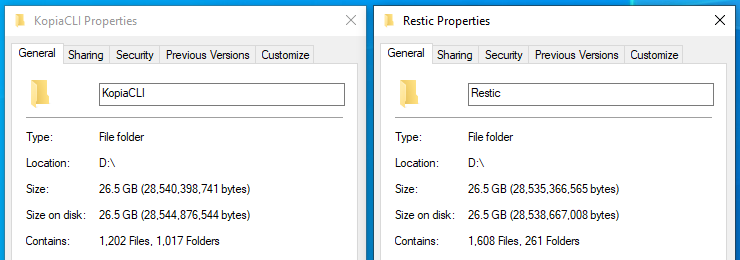
Somehow my ~11TB backup that took 24 hours ended up being essentially the same size as the original data despite deduplication and max compression. Here’s the command I used:
> restic --repo MyBackup --compression max --option local.connections=1 --read-concurrency 1 backup --no-scan E:\Archive E:\Docs E:\Media...
Strangely enough, it seems auto compression was used despite me specifying max?
> restic --repo MyBackup stats --mode restore-size latest
enter password for repository:
repository 7e3b08e1 opened (version 2, compression level auto)
[0:09] 100.00% 203 / 203 index files loaded
scanning...
Stats in restore-size mode:
Snapshots processed: 1
Total File Count: 1383286
Total Size: 10.990 TiB
> restic --repo MyBackup stats --mode raw-data
enter password for repository:
repository 7e3b08e1 opened (version 2, compression level auto)
[0:08] 100.00% 203 / 203 index files loaded
scanning...
Stats in raw-data mode:
Snapshots processed: 1
Total Blob Count: 8932672
Total Uncompressed Size: 10.716 TiB
Total Size: 10.607 TiB
Compression Progress: 100.00%
Compression Ratio: 1.01x
Compression Space Saving: 1.01%
Is this just a case of unrealistic expectations or did I mess up somewhere? I know for a fact there are dupes and near-dupes on the drive, and all the deduplication and compression benchmarks and posts I came across show far better savings, even ones where restic didn’t come out the winner.