I’m trying to restore ~230G archive file from repository served by rest-server.
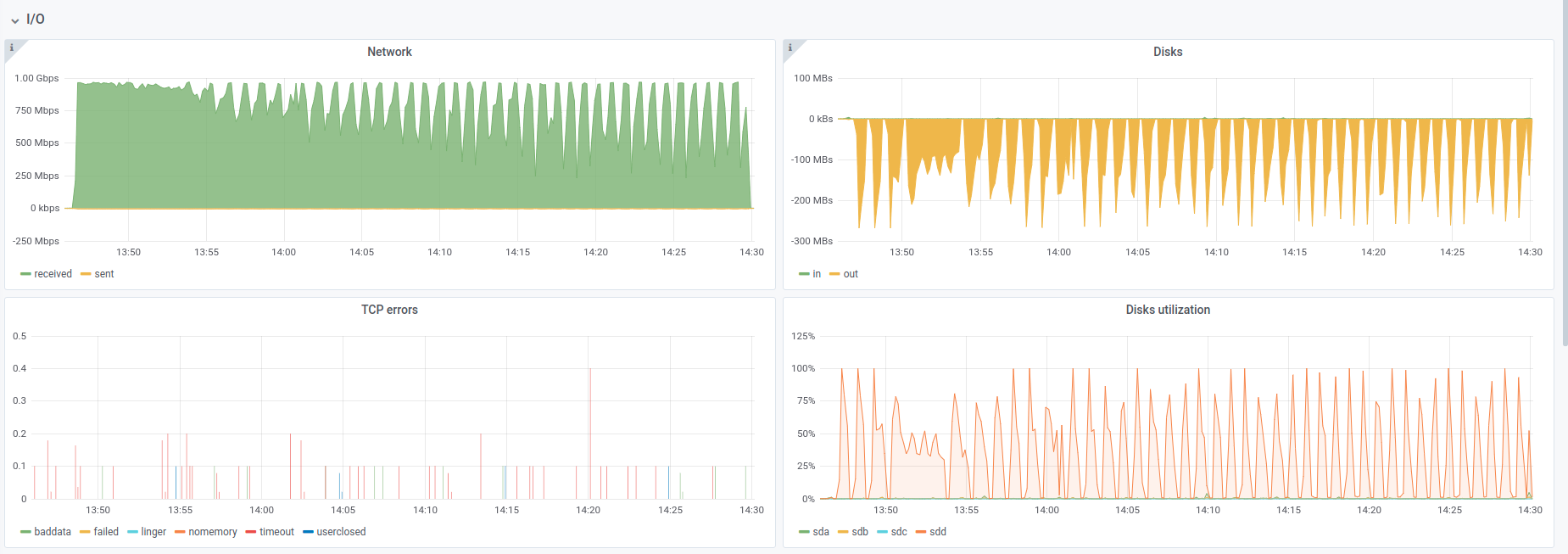
Today I looked at our Grafana and found in I/O panel that network and disk usage had saw-like graphs while running restic restore. In the picture below looks like restic downloads some data, saturates network connection while keeping block write low, after some time (~40s) network usage drops, and restic performs write to disk, causing block i/o spike in graphs.
Restore runs 8 concurrent workers, each of which downloads a pack file from repository, then writes pack blobs to the target files. 8-way concurrency should smooth out worker download-write serialization (and it did in my tests), but I can’t explain the network and disk utilization you observe. It is possible that 8 concurrent downloads isn’t enough to fully utilize your remote repository (what is it, btw?). Or you may be limited by local CPU.
I’d start by measuring max sustained repository download speed (e.g., download bunch of files using rclone or curl into /dev/null), as well as max sustained target filesystem write speed. This will tell you how close restic restore gets to the max and hopefully give an idea where the bottleneck is.
CPU utilization isn’t the cause, I think: none of the cores were loaded even on half.
Repository is just folder on RAID0 of four disks, managed by mdadm. Each of disks was loaded on 30-40% while restore. Repo served by rest-server latest version.
Here’s the graphs of rclone sync and rsync respectively. Network was saturated evenly.
How much slower average restic restore compared to rclone? Is your target filesystem on directly attached mechanical drive or something else, and what filesystem type do you have there? Are you restoring few large files (multiple GB each) or many small files (few MB each)?
If you can provide a test repository and steps I can use to reproduce the problem in AWS, I’ll try to have a closer look. (obviously, use random bytes, not real data if you decide to provide the test repo).
Restic with rest-server took 44 minutes, rclone with sftp - 45 minutes, rsync - 40. Everything looks fine, and restic does its job well… maybe I was worrying too much about those graphs =)
I wonder if this is filesystem cache filling up and flushing that causes download stuttering. Can you check if adding File.Sync like below to restore fileswriter.go will smooth things out?